
când vine vorba de operaționalizarea datelor de jurnal, HAProxy oferă o multitudine de informații. În această postare pe blog, demonstrăm cum să configurați logarea HAProxy, să vizați un server Syslog, să înțelegeți câmpurile de jurnal și să sugerați câteva instrumente utile pentru analizarea fișierelor jurnal.
Se arunca cu capul adânc în HAProxy logare
HAProxy stă în calea critică a infrastructurii. Indiferent dacă este utilizat ca echilibrator de sarcină de margine, sidecar sau ca controler Kubernetes ingress, obținerea de jurnale semnificative din HAProxy este un must-have.
logarea vă oferă informații despre fiecare conexiune și solicitare. Permite observabilitatea necesară pentru depanare și poate fi utilizată chiar și pentru detectarea timpurie a problemelor. Este una dintre multele modalități de a obține informații de la HAProxy. Alte modalități includ obținerea de valori folosind pagina de statistici sau API-ul Runtime, configurarea alertelor prin e-mail și utilizarea diferitelor integrări open-source pentru stocarea jurnalului sau a datelor statistice în timp. HAProxy oferă jurnale foarte detaliate cu precizie de milisecunde și generează o multitudine de informații despre traficul care curge în infrastructura dvs. Aceasta include:
- valori despre trafic: date de sincronizare, contoare de conexiuni, dimensiunea traficului etc.
- informații despre deciziile HAProxy: schimbarea conținutului, filtrarea, persistența etc.
- informații despre solicitări și răspunsuri: anteturi, coduri de stare, sarcini utile etc.
- starea de terminare a unei sesiuni și capacitatea de a urmări în cazul în care apar eșecuri (partea de client, partea de server?)
în această postare, veți învăța cum să configurați înregistrarea HAProxy și cum să citiți mesajele de jurnal pe care le generează. Vom enumera apoi câteva instrumente pe care le veți găsi utile atunci când operaționalizați datele dvs. de jurnal.
Server Syslog
HAProxy poate emite un mesaj jurnal pentru procesare de către un server syslog. Acest lucru este compatibil cu instrumentele syslog familiare precum Rsyslog, precum și cu noul serviciu systemd journald. Puteți utiliza, de asemenea, diverse expeditori de jurnal, cum ar fi Logstash și Fluentd, pentru a primi mesaje Syslog de la HAProxy și a le expedia către un agregator central de jurnal.
dacă lucrați într-un mediu de containere, HAProxy acceptă înregistrarea nativă în cloud, care vă permite să trimiteți mesajele de jurnal către stdout și stderr. În acest caz, treceți la următoarea secțiune unde veți vedea cum.
înainte de a analiza modul de activare a jurnalului prin fișierul de configurare HAProxy, trebuie mai întâi să vă asigurați că aveți un server Syslog, cum ar fi rsyslog, configurat pentru a primi jurnalele. Pe Ubuntu, ați instala rsyslog folosind managerul de pachete apt, așa:
odată ce rsyslog este instalat, editați configurația acestuia pentru a gestiona ingerarea mesajelor de jurnal HAProxy. Adăugați următoarele fie la / etc / rsyslog.conf sau la un fișier nou în cadrul rsyslog.D Director, cum ar fi/etc / rsyslog.d / haproxy.conf:
apoi, reporniți serviciul rsyslog. În exemplul de mai sus, rsyslog ascultă pe adresa IP loopback, 127.0.0.1, pe portul UDP implicit 514. Acest config special scrie la două fișiere jurnal. Fișierul ales se bazează pe nivelul de severitate cu care a fost înregistrat mesajul. Pentru a înțelege acest lucru, aruncați o privire mai atentă la ultimele două linii din fișier. Ei încep astfel:
standardul Syslog prevede că fiecărui mesaj înregistrat trebuie să i se atribuie un cod de facilitate și un nivel de severitate. Având în vedere exemplul de configurare rsyslog de mai sus, puteți presupune că vom configura HAProxy pentru a trimite toate mesajele sale de jurnal cu un cod de facilitate local0.
nivelul de severitate este specificat după codul instalației, separat printr-un punct. Aici, prima linie captează mesaje la toate nivelurile de severitate și le scrie într-un fișier numit haproxy-traffic.jurnal. A doua linie captează numai mesaje la nivel de notificare și mai sus, conectându-le la un fișier numit haproxy-admin.jurnal.
HAProxy este hardcoded pentru a utiliza anumite niveluri de severitate la trimiterea anumitor mesaje. De exemplu, clasifică mesajele jurnal legate de conexiuni și solicitări HTTP cu nivelul de severitate a informațiilor. Alte evenimente sunt clasificate folosind unul dintre celelalte niveluri, mai puțin detaliate. De la cel mai puțin important la cel mai puțin important, nivelurile de severitate sunt:
| nivel de severitate | jurnale HAProxy |
| Emerg | erori precum epuizarea descriptorilor de fișiere ai sistemului de operare. |
| alertă | unele cazuri rare în care s-a întâmplat ceva neașteptat, cum ar fi imposibilitatea de a memora în cache un răspuns. |
| crit | nu este utilizat. |
| err | erori cum ar fi imposibilitatea de a analiza un fișier hartă, imposibilitatea de a analiza fișierul de configurare HAProxy și atunci când o operație pe un tabel stick eșuează. |
| avertisment | anumite erori importante, dar non-critice, cum ar fi faptul că nu setați un antet de solicitare sau nu vă conectați la un server de nume DNS. |
| notă | modificări la starea unui server, cum ar fi în sus sau în jos sau atunci când un server este dezactivat. Sunt incluse și alte evenimente la pornire, cum ar fi proxy-urile de pornire și modulele de încărcare. Înregistrarea în jurnal a verificării sănătății, dacă este activată, folosește și acest nivel. |
| info | conexiune TCP și HTTP detalii cerere și erori. |
| debug | puteți scrie cod Lua personalizat care Înregistrează mesajele de depanare |
distribuțiile Linux moderne sunt livrate împreună cu managerul de servicii systemd, care introduce journald pentru colectarea și stocarea jurnalelor. Serviciul journald nu este o implementare Syslog, dar este compatibil Syslog, deoarece va asculta pe același soclu /dev/log. Acesta va colecta jurnalele primite și va permite utilizatorului să le filtreze după codul facilității și/sau nivelul de severitate folosind câmpurile journald echivalente (SYSLOG_FACILITY, PRIORITY).
HAProxy Logging Configuration
manualul de configurare HAProxy explică faptul că logarea poate fi activată în doi pași: primul este să specificați un server Syslog în secțiuneaglobal utilizând olog directivă:
log
logdirectiva instruiește HAProxy să trimită jurnale la serverul syslog ascultând la 127.0.0.1:514. Mesajele sunt trimise cu facilitatea local0, care este una dintre facilitățile standard, definite de utilizator Syslog. Este, de asemenea, facilitatea pe care o așteaptă configurația noastră rsyslog. Puteți adăuga mai multelogdeclarație pentru a trimite ieșire la mai multe servere Syslog.
puteți controla cât de multe informații sunt înregistrate adăugând un nivel de Syslog la sfârșitul liniei:
al doilea pas pentru configurarea înregistrării este actualizarea diferitelor proxy-uri (frontendbackend șilisten secțiuni) pentru a trimite mesaje la serverul(serverele) syslog configurate în secțiuneaglobal. Acest lucru se face prin adăugarea unei directive log global. Puteți să o adăugați la secțiuneadefaults, așa cum se arată:
Directivalog global spune practic, Utilizați linialog care a fost setată în secțiuneaglobal. Punerea unei directivelog global în secțiunea defaults este echivalentă cu introducerea acesteia în toate secțiunile proxy ulterioare. Deci, acest lucru va permite logarea pe toate proxy-urile. Puteți citi mai multe despre secțiunile unui fișier de configurare HAProxy în blogul nostru postați cele patru secțiuni esențiale ale unei configurații HAProxy.
în mod implicit, ieșirea din HAProxy este minimă. Adăugarea liniei option httplog la secțiunea defaults va permite înregistrarea HTTP mai detaliată, pe care o vom explica mai detaliat mai târziu.
o configurație tipică HAProxy arată astfel:
Utilizarea regulilor globale de logare este cea mai comună configurare HAProxy, dar le puteți pune direct într-o secțiunefrontend. Poate fi util să aveți o configurație de înregistrare diferită ca unică. De exemplu, este posibil să doriți să indicați spre un server syslog țintă diferit, să utilizați o instalație de înregistrare diferită sau să capturați niveluri de severitate diferite, în funcție de cazul de utilizare al aplicației backend. Luați în considerare următorul exemplu în care secțiunile frontend, fe_site1 și fe_site2, setează diferite adrese IP și niveluri de severitate:
când vă conectați la un serviciu local Syslog, scrierea într-un soclu UNIX poate fi mai rapidă decât direcționarea adresei TCP loopback. În general, pe sistemele Linux, un soclu UNIX care ascultă mesajele Syslog este disponibil la /dev/log, deoarece aici este funcția syslog() a Bibliotecii GNU C trimite mesaje în mod implicit. Vizați soclul UNIX astfel:
cu toate acestea, ar trebui să rețineți că, dacă veți utiliza un soclu UNIX pentru înregistrare și, în același timp, rulați HAProxy într—un mediu chrooted—sau lăsați HAProxy să creeze un directorchroot pentru dvs. utilizând Directiva de configurare chroot-atunci soclul UNIX trebuie să fie disponibil în acel director chroot. Acest lucru se poate face într-unul din cele două moduri.
În primul rând, atunci când rsyslog pornește, se poate crea un nou soclu de ascultare în cadrul sistemului de fișiere chroot. Adăugați următoarele la fișierul de configurare HAProxy rsyslog:
a doua modalitate este să adăugați manual soclul la sistemul de fișiere chroot utilizând comandamount cu opțiunea--bind.
asigurați-vă că adăugați o intrare în fișierul /etc/fstab sau într-un fișier de unitate systemd, astfel încât montura să persiste după repornire. După ce ați configurat înregistrarea în jurnal, veți dori să înțelegeți cum sunt structurate mesajele. În secțiunea următoare, veți vedea câmpurile care alcătuiesc jurnalele de nivel TCP și HTTP.
dacă trebuie să limitați cantitatea de date stocate, o modalitate este să eșantionați doar o porțiune de mesaje de jurnal. Setați nivelul jurnalului la Silențios pentru un număr aleatoriu de solicitări, astfel:
rețineți că, dacă este posibil, este mai bine să capturați cât mai multe date. În acest fel, nu aveți informații lipsă atunci când aveți nevoie cel mai mult. De asemenea, puteți modifica expresia ACL, astfel încât anumite condiții să suprascrie regula.
O altă modalitate de a limita numărul de mesaje înregistrate este să setațioption dontlog-normal îndefaults saufrontend. În acest fel, sunt capturate doar timeout-uri, încercări și erori. Probabil că nu doriți să activați acest lucru tot timpul, dar numai în anumite perioade, cum ar fi atunci când efectuați teste de benchmarking.
Dacă executați HAProxy în interiorul unui container Docker și utilizați HAProxy versiunea 1.9, apoi în loc de a trimite ieșire jurnal la un server Syslog puteți trimite la stdout și / sau stderr. Setați adresa la stdoutsaustderr, respectiv. În acest caz, este de asemenea de preferat să setați formatul mesajului la raw, astfel:
HAProxy Log Format
tipul de înregistrare pe care îl veți vedea este determinat de modul proxy pe care l-ați setat în HAProxy. HAProxy poate funcționa fie ca un proxy layer 4 (TCP), fie ca proxy Layer 7 (HTTP). Modul TCP este implicit. În acest mod, se stabilește o conexiune full-duplex între clienți și servere și nu se va efectua nicio examinare layer 7. Dacă ați setat configurația rsyslog pe baza discuției noastre din prima secțiune, Veți găsi fișierul jurnal la /var/log/haproxy-traffic.jurnal.
când este în modul TCP, care este setat prin adăugareamode tcp, ar trebui să adăugați și opțiunea tcplog. Cu această opțiune, formatul jurnalului este implicit la o structură care oferă informații utile, cum ar fi detaliile conexiunii Layer 4, cronometrele, numărul de octeți etc. Dacă ar fi să recreați acest format folosind log-format, care este folosit pentru a seta un format personalizat, ar arăta astfel:
descrierile acestor câmpuri pot fi găsite în documentația formatului jurnalului TCP, deși vom descrie mai multe în secțiunea viitoare.
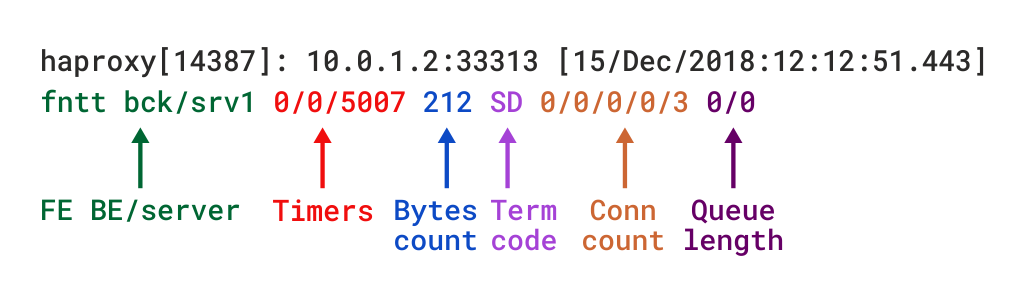
TCP log format în HAProxy
când HAProxy este rulat ca un proxy Layer 7 prinmode http, ar trebui să adăugați opțiunea httplog directivă. Se asigură că cererile și răspunsurile HTTP sunt analizate în profunzime și că niciun conținut compatibil cu RFC nu va rămâne necapturat. Acesta este modul care evidențiază cu adevărat valoarea diagnostică a HAProxy. Formatul jurnalului HTTP oferă același nivel de informații ca și formatul TCP, dar cu date suplimentare specifice protocolului HTTP. Dacă ar fi să recreați acest format folosind log-format, ar arăta astfel:
descrieri detaliate ale diferitelor câmpuri pot fi găsite în documentația formatului jurnalului HTTP.
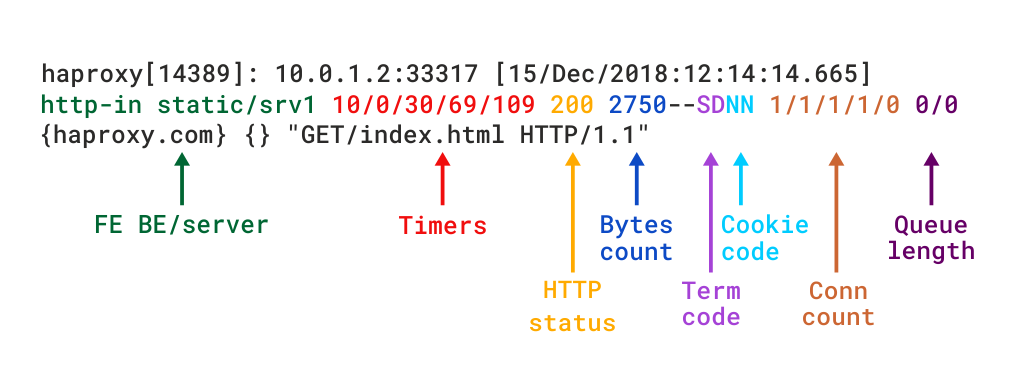
HTTP log format în HAProxy
de asemenea, puteți defini un format de jurnal personalizat, capturând doar ceea ce aveți nevoie. Utilizați Directivalog-format (sau log-format-sd pentru syslog de date structurate) în defaults sau frontend. Citiți postarea noastră pe blog HAProxy log Customization pentru a afla mai multe și a vedea câteva exemple.
în următoarele secțiuni, vă veți familiariza cu câmpurile incluse atunci când utilizați option tcplog sau option httplog.
proxy-uri
în fișierul jurnal produs, fiecare linie începe cu interfața, backend-ul și serverul către care a fost trimisă solicitarea. De exemplu, dacă ați avut următoarea configurație HAProxy, veți vedea linii care descriu cererile ca fiind rutate prin interfața http-in către backend static și apoi către serverul srv1.
aceasta devine informație vitală atunci când trebuie să știți unde a fost trimisă o solicitare, cum ar fi atunci când vedeți erori care afectează doar unele dintre serverele dvs.
cronometre
cronometre sunt furnizate în milisecunde și acoperă evenimentele care au loc în timpul unei sesiuni. Cronometrele capturate de formatul implicit al Jurnalului TCP sunt Tw / Tc / TT. Cele furnizate de formatul de jurnal HTTP implicit sunt TR/ Tw / Tc / Tr / Ta. Acestea se traduc ca:
| Timer | adică |
| TR | timpul total pentru a obține cererea clientului (numai în modul HTTP). |
| Tw | timpul total petrecut în cozile de așteptare pentru un slot de conectare. |
| Tc | timpul total pentru a stabili conexiunea TCP la server. |
| Tr | timpul de răspuns al serverului (numai în modul HTTP). |
| Ta | timpul total activ pentru solicitarea HTTP (numai în modul HTTP). |
| Tt | durata totală a sesiunii TCP, între momentul în care proxy-ul a acceptat-o și momentul în care ambele capete au fost închise. |
veți găsi o descriere detaliată a tuturor cronometrelor disponibile în documentația HAProxy. Următoarea diagramă demonstrează, de asemenea, unde se înregistrează timpul în timpul unei singure tranzacții end-to-end. Rețineți că liniile violete de pe margini denotă cronometre.
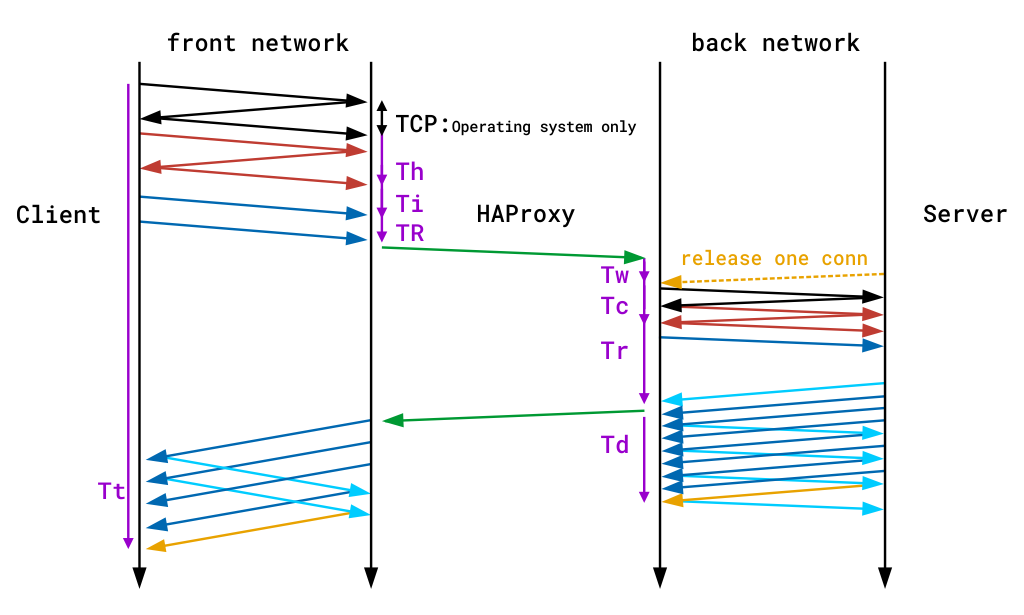
înregistrarea timpului în timpul unei singure tranzacții end-to-end
starea sesiunii la deconectare
atât jurnalele TCP, cât și HTTP includ un cod de stare de terminare care vă spune modul în care s-a încheiat sesiunea TCP sau HTTP. Este un cod de două caractere. Primul caracter raportează primul eveniment care a determinat încheierea sesiunii, în timp ce al doilea raportează starea sesiunii TCP sau HTTP când a fost închisă.
iată câteva exemple de cod de terminare:
| cod de două caractere | semnificație |
| – | terminare normală pe ambele părți. |
| cD | clientul nu a trimis și nu a recunoscut niciun fel de date și în cele din următimeout client a expirat. |
| SC | serverul a refuzat în mod explicit conexiunea TCP. |
| PC | proxy-ul a refuzat să stabilească o conexiune la server, deoarece limita de soclu a procesului a fost atinsă în timp ce încerca să se conecteze. |
există o mare varietate de motive pentru care o conexiune ar fi putut fi închisă. Informații detaliate despre toate codurile de terminare posibile pot fi găsite în documentația HAProxy.
contoare
contoare indică starea de sănătate a sistemului atunci când o cerere a trecut prin. HAProxy înregistrează cinci contoare pentru fiecare conexiune sau cerere. Ele pot fi de neprețuit pentru a determina câtă sarcină este plasată pe sistem, unde sistemul rămâne în urmă și dacă limitele au fost atinse. Când vă uitați la o linie din jurnal, veți vedea contoarele listate ca cinci numere separate prin bare oblice: 0/0/0/0/0.
în modul TCP sau HTTP, acestea se descompun ca:
- numărul total de conexiuni concurente din procesul HAProxy când sesiunea a fost înregistrată.
- numărul total de conexiuni concurente rutate prin acest
frontendcând sesiunea a fost înregistrată. - numărul total de conexiuni concurente direcționate către acest
backendcând sesiunea a fost înregistrată. - numărul total de conexiuni concurente încă active pe acest
servercând sesiunea a fost înregistrată. - numărul de încercări încercate atunci când încercați să vă conectați la serverul backend.
alte domenii
HAProxy nu înregistrează totul out-of-the-box, dar puteți tweak-l pentru a capta ceea ce ai nevoie. Un antet de solicitare HTTP poate fi înregistrat prin adăugarea Directiveihttp-request capture:
jurnalul va afișa anteturi între bretele ondulate și separate prin simboluri de țeavă. Aici puteți vedea anteturile gazdă și agent utilizator pentru o solicitare:
un antet de răspuns poate fi înregistrat prin adăugarea unei directivehttp-response capture:
în acest caz, trebuie să adăugați și o directivădeclare capture response, care alocă un slot de captare în care antetul de răspuns, Odată ajuns, poate fi stocat. Fiecare slot pe care îl adăugați este atribuit automat un ID pornind de la zero. Faceți referire la acest ID atunci când apelați http-response capture. Anteturile de răspuns sunt înregistrate după anteturile de solicitare, într-un set separat de bretele ondulate.
Valorile Cookie-urilor pot fi înregistrate într-un mod similar cu Directivahttp-request capture.
orice capturat cuhttp-request capture, inclusiv anteturile HTTP și cookie-urile, va apărea în același set de acolade. Același lucru este valabil pentru orice capturat cu http-response capture.
de asemenea, puteți utilizahttp-request capture pentru a înregistra datele eșantionate din tabelele stick. Dacă urmăriți ratele de solicitare ale utilizatorilor cu un stick-table, le puteți înregistra astfel:
deci, efectuarea unei cereri către o pagină web care conține documentul HTML și două imagini ar arăta rata de solicitare concurentă a utilizatorului crescând la trei:
de asemenea, puteți înregistra valorile metodelor de preluare, cum ar fi înregistrarea versiunii SSL/TLS care a fost utilizată (rețineți că există o variabilă de jurnal încorporată pentru a obține acest lucru numit %sslv):
variabilele setate cuhttp-request set-var pot fi, de asemenea, înregistrate.
expresiile ACL evaluează fie adevărat, fie fals. Nu le puteți înregistra direct, dar puteți seta o variabilă în funcție de dacă expresia este adevărată. De exemplu, dacă utilizatorul vizitează /api, puteți seta o variabilă numită req.is_api la o valoare a API-ului Is și apoi să o capturați în jurnale.
activarea profilării HAProxy
odată cu lansarea HAProxy 1.9, puteți înregistra timpul CPU petrecut pentru procesarea unei cereri în cadrul HAProxy. Adăugați Directiva profiling.tasks la secțiunea global:
există noi metode de preluare care expun valorile de profilare:
| metoda fetch | descriere |
date_us |
partea microsecunde a datei. |
cpu_calls |
numărul de apeluri către sarcina care procesează fluxul sau cererea curentă de când a fost alocată. Este resetat pentru fiecare nouă solicitare pe aceeași conexiune. |
cpu_ns_avg |
numărul mediu de nanosecunde petrecut în fiecare apel la sarcina de prelucrare a fluxului sau cererea curentă. |
cpu_ns_tot |
numărul total de nanosecunde petrecute în fiecare apel la sarcina de procesare a fluxului sau cererea curentă. |
lat_ns_avg |
numărul mediu de nanosecunde petrecute între momentul în care sarcina care gestionează fluxul este trezită și momentul în care este apelată efectiv. |
lat_ns_tot |
numărul total de nanosecunde între momentul în care sarcina care gestionează fluxul este trezită și momentul în care este apelată efectiv. |
adăugați aceste mesaje de jurnal ca aceasta:
aceasta este o modalitate foarte bună de a evalua care Cereri costa cel mai mult pentru a procesa.
analiza jurnalelor HAProxy
după cum ați învățat, HAProxy are o mulțime de câmpuri care oferă o cantitate imensă de informații despre conexiuni și solicitări. Cu toate acestea, citirea lor directă poate duce la supraîncărcarea informațiilor. De multe ori, este mai ușor să le analizați și să le agregați cu instrumente externe. În această secțiune, veți vedea unele dintre aceste instrumente și modul în care acestea pot utiliza informațiile de logare furnizate de HAProxy.
HALog
HALog este un instrument de analiză jurnal mic, dar puternic, care este livrat cu HAProxy. Acesta a fost conceput pentru a fi implementat pe serverele de producție, unde poate ajuta la depanarea manuală, cum ar fi atunci când se confruntă cu probleme live. Este extrem de rapid și capabil să analizeze jurnalele TCP și HTTP la 1 până la 2 GB pe secundă. Trecându-i o combinație de steaguri, puteți extrage informații statistice din jurnale, inclusiv cereri pe URL și cereri pe IP sursă. Apoi, puteți sorta după timpul de răspuns, rata de eroare și Codul de terminare.
de exemplu, dacă doriți să extrageți statistici per server din jurnale, puteți utiliza următoarea comandă:
acest lucru este util atunci când trebuie să analizați liniile de jurnal pe codul de stare și să descoperiți rapid dacă un anumit server este nesănătos (de exemplu, returnând prea multe răspunsuri 5xx). Sau, un server poate refuza prea multe cereri (răspunsuri 4xx), ceea ce este un semn al unui atac de forță brută. De asemenea, puteți obține timpul mediu de răspuns pe server cu coloana avg_rt, care este utilă pentru depanare.
cu HALog, puteți obține statistici per-URL utilizând următoarea comandă:
rezultatul arată numărul de solicitări, numărul de erori, timpul total de calcul, timpul mediu de calcul, timpul total de calcul al cererilor reușite, timpul mediu de calcul al cererilor reușite, numărul mediu de octeți trimiși și numărul total de octeți trimiși. În plus față de analiza statisticilor serverului și URL-ului, puteți aplica mai multe filtre pentru a potrivi jurnalele cu un timp de răspuns dat, cod de stare HTTP, cod de terminare a sesiunii etc.
HAProxy Stats Page
analiza jurnalelor cu HALog nu este singura modalitate de a obține valori din HAProxy. Pagina HAProxy Stats poate fi activată prin adăugarea Directiveistats enable la o secțiunefrontend saulisten. Afișează statistici live ale serverelor dvs. Următoarea secțiunelisten începe să asculte pagina de statistici pe portul 8404:
pagina de statistici este foarte utilă pentru a obține informații instantanee despre traficul care curge prin HAProxy. Ea nu stochează aceste date, deși, și afișează date numai pentru un singur echilibrator de sarcină.
Tabloul de bord HAProxy Enterprise în timp real
dacă utilizați HAProxy Enterprise, atunci aveți acces la tabloul de bord în timp real. În timp ce pagina Statistici afișează statistici pentru o singură instanță de HAProxy, Tabloul de bord în timp real agregă și afișează informații într-un grup de echilibratori de sarcină. Acest lucru îl face ușor pentru a observa starea de sănătate a tuturor serverelor de la un singur ecran. Datele pot fi vizualizate timp de până la 30 de minute.
tabloul de bord stochează și afișează informații despre starea serviciului, ratele de solicitare și încărcarea. De asemenea, facilitează îndeplinirea sarcinilor administrative, cum ar fi activarea, dezactivarea și drenarea backend-urilor. Dintr-o privire, puteți vedea care servere sunt în sus și pentru cât timp. De asemenea, puteți vizualiza datele tabelului stick, care, în funcție de urmărirea tabelului stick, vă pot afișa rate de eroare, rate de solicitare și alte informații în timp real despre utilizatorii dvs. Datele tabelului Stick pot fi agregate, de asemenea.
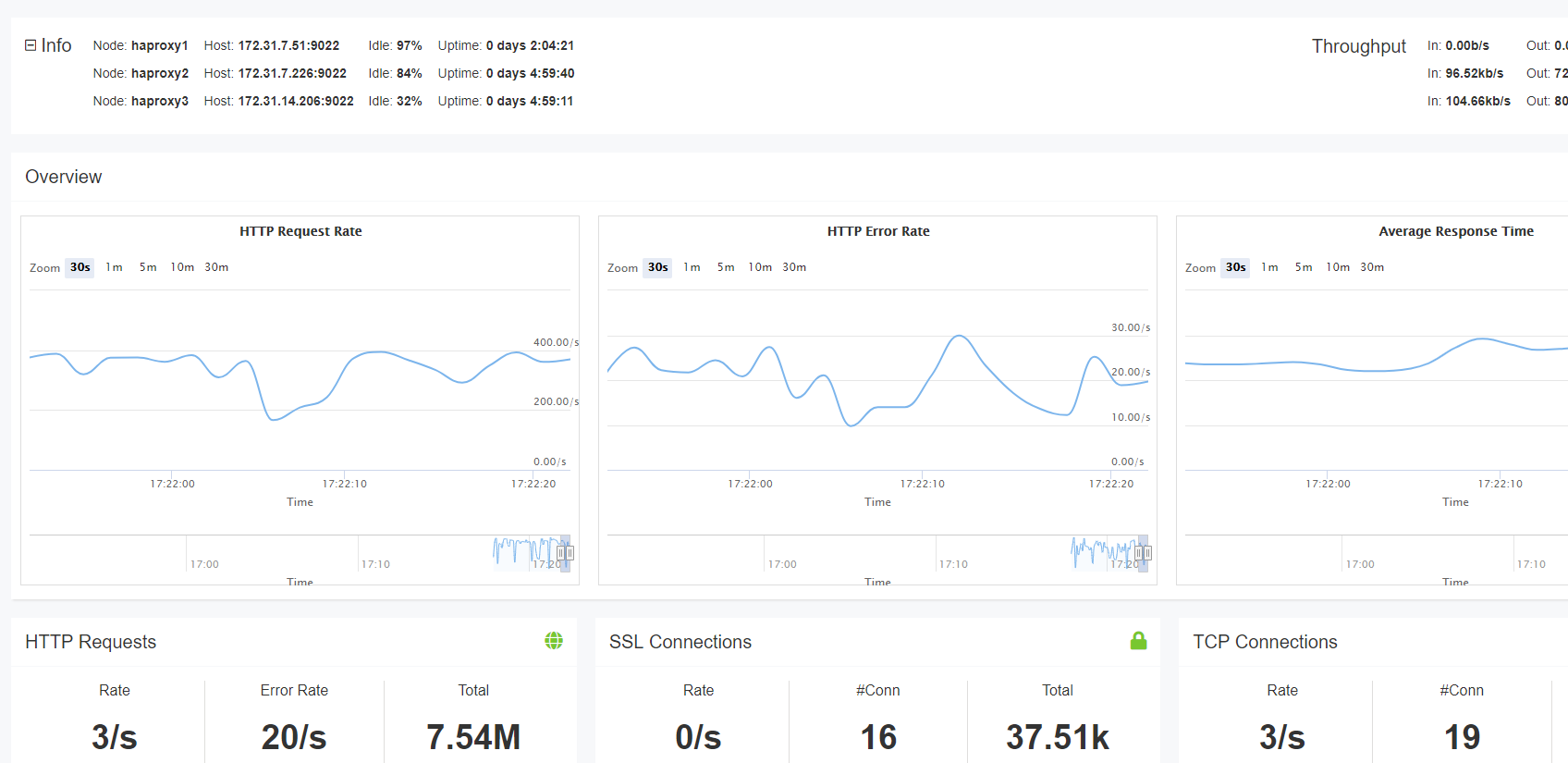
Tabloul de bord în timp real din HAProxy Enterprise
Tabloul de bord în timp real este unul dintre numeroasele suplimente disponibile cu HAProxy Enterprise.
concluzie
În această postare pe blog, ați învățat cum să configurați logarea HAProxy pentru a obține observabilitatea asupra echilibratorului de sarcină, care este o componentă critică în infrastructura dvs. HAProxy emite mesaje Syslog detaliate atunci când funcționează în modul TCP și HTTP. Acestea pot fi trimise la un număr de instrumente de logare, cum ar fi rsyslog.
HAProxy se livrează cu utilitarul de linie de comandă HALog, care simplifică analizarea datelor jurnalului atunci când aveți nevoie de informații despre tipurile de răspunsuri pe care le primesc utilizatorii și încărcarea pe serverele dvs. De asemenea, puteți obține o imagine vizuală a stării de sănătate a serverelor dvs. utilizând pagina HAProxy Stats sau tabloul de bord HAProxy Enterprise în timp real.
vrei să știi când este publicat un astfel de conținut? Abonați-vă la acest blog sau urmați-ne pe Twitter. De asemenea, vă puteți alătura conversației pe Slack! HAProxy Enterprise combină HAProxy cu caracteristici enterprise-class, cum ar fi tabloul de bord în timp real, și suport premium. Contactați-ne pentru a afla mai multe sau înscrieți-vă pentru o încercare gratuită astăzi!