
När det gäller att operationalisera dina loggdata, HAProxy ger en mängd information. I det här blogginlägget visar vi hur man ställer in HAProxy-loggning, riktar sig mot en Syslog-server, förstår loggfälten och föreslår några användbara verktyg för att analysera loggfiler.
djupdykning i HAProxy loggning
HAProxy sitter i den kritiska vägen för din Infrastruktur. Oavsett om det används som en kantbelastningsbalanserare, en sidovagn eller som en Kubernetes ingress controller, är det ett måste att få meningsfulla loggar ut ur HAProxy.
loggning ger dig insikter om varje anslutning och begäran. Det möjliggör observerbarhet som behövs för felsökning och kan även användas för att upptäcka problem tidigt. Det är ett av de många sätten att få information från HAProxy. Andra sätt är att få mätvärden med hjälp av statistiksidan eller Runtime API, ställa in e-postvarningar och använda de olika Open source-integrationerna för att lagra logg eller statistisk data över tiden. HAProxy ger mycket detaljerade loggar med millisekund noggrannhet och genererar en mängd information om trafik som flyter in i din Infrastruktur. Detta inkluderar:
- mätvärden om trafiken: tidsdata, anslutningsräknare, trafikstorlek etc.
- Information om haproxybeslut: innehållsbyte, filtrering, uthållighet etc.
- Information om förfrågningar och svar: rubriker, statuskoder, nyttolaster etc.
- Avslutningsstatus för en session och möjligheten att spåra var fel uppstår (klientsida, serversida?)
i det här inlägget lär du dig hur du konfigurerar HAProxy-loggning och hur du läser loggmeddelandena som den genererar. Vi listar sedan några verktyg som du tycker är användbara när du opererar dina loggdata.
Syslog Server
HAProxy kan avge loggmeddelande för bearbetning av en syslog server. Detta är kompatibelt med bekanta syslog-verktyg som Rsyslog, liksom den nyare systemd service journald. Du kan också använda olika log speditörer som Logstash och Fluentd att ta emot Syslog meddelanden från HAProxy och skicka dem till en central log aggregator.
Om du arbetar i en containermiljö stöder HAProxy molnbaserad loggning som låter dig skicka loggmeddelandena till stdout och stderr. Hoppa i så fall till nästa avsnitt där du ser hur.
innan du tittar på hur du aktiverar loggning via HAProxy-konfigurationsfilen bör du först se till att du har en Syslog-server, till exempel rsyslog, konfigurerad för att ta emot loggarna. På Ubuntu skulle du installera rsyslog med apt-pakethanteraren, så här:
När rsyslog är installerat, redigera dess konfiguration för att hantera intag av HAProxy-loggmeddelanden. Lägg till följande antingen till / etc / rsyslog.conf eller till en ny fil i rsyslog.d katalog, tycka om / etc / rsyslog.d / haproxy.conf:
starta sedan om rsyslog-tjänsten. I exemplet ovan lyssnar rsyslog på IP loopback-adressen, 127.0.0.1, på standard UDP-porten 514. Denna speciella konfiguration skriver till två loggfiler. Den valda filen baseras på svårighetsgraden med vilken meddelandet loggades. För att förstå detta, ta en närmare titt på de två sista raderna i filen. De börjar så här:
Syslog-standarden föreskriver att varje loggat meddelande ska tilldelas en anläggningskod och en svårighetsgrad. Med tanke på exemplet rsyslog-konfiguration ovan kan du anta att vi konfigurerar HAProxy för att skicka alla sina loggmeddelanden med en anläggningskod för local0.
svårighetsgraden anges efter anläggningskoden, separerad med en punkt. Här fångar den första raden meddelanden på alla svårighetsgrader och skriver dem till en fil som heter haproxy-traffic.logga. Den andra raden fångar bara meddelanden på meddelandenivå och högre och loggar dem till en fil som heter haproxy-admin.logga.
HAProxy är hårdkodad för att använda vissa svårighetsgrader när du skickar vissa meddelanden. Det kategoriserar till exempel loggmeddelanden relaterade till anslutningar och HTTP-förfrågningar med informationens svårighetsgrad. Andra händelser kategoriseras med en av de andra, mindre detaljerade nivåerna. Från de flesta till minst viktiga är svårighetsgraden:
| svårighetsgrad | HAProxy loggar |
| emerg | fel som att ta slut på operativsystemfilbeskrivningar. |
| varning | några sällsynta fall där något oväntat har hänt, till exempel att det inte går att cacha ett svar. |
| crit | används inte. |
| err | fel som att inte kunna tolka en kartfil, att inte kunna tolka HAProxy konfigurationsfilen, och när en operation på en pinne tabell misslyckas. |
| varning | vissa viktiga, men icke-kritiska, fel som att inte ställa in en förfrågningshuvud eller inte ansluta till en DNS-namnserver. |
| meddelande | ändras till en servers tillstånd, till exempel att vara upp eller ner eller när en server är inaktiverad. Andra händelser vid start, till exempel startproxyservrar och laddningsmoduler ingår också. Hälsokontrollloggning, om den är aktiverad, använder också denna nivå. |
| info | TCP-anslutning och HTTP-begäran detaljer och fel. |
| debug | du kan skriva anpassad Lua-kod som loggar felsökningsmeddelanden |
moderna Linux-distributioner levereras med service manager systemd, som introducerar journald för insamling och lagring av loggar. Journald-tjänsten är inte en syslog-implementering, men den är Syslog-kompatibel eftersom den kommer att lyssna på samma /dev/log-uttag. Det kommer att samla de mottagna loggarna och låta användaren filtrera dem efter anläggningskod och/eller svårighetsgrad med hjälp av motsvarande journalfält (SYSLOG_FACILITY, PRIORITY).
HAProxy Loggningskonfiguration
HAProxy-konfigurationsmanualen förklarar att loggning kan aktiveras med två steg: det första är att ange en Syslog-server i avsnittetglobal genom att använda ettlog direktiv:
log div > direktivet instruerar HAProxy att skicka loggar till syslog server lyssna på 127.0.0.1:514. Meddelanden skickas med facility local0, som är en av de vanliga, användardefinierade Syslog anläggningar. Det är också den anläggning som vår rsyslog-konfiguration förväntar sig. Du kan lägga till mer än ett log – uttalande för att skicka utdata till flera Syslog-servrar.
Du kan styra hur mycket information som loggas genom att lägga till en Syslog-nivå i slutet av raden:
det andra steget för att konfigurera loggning är att uppdatera de olika proxyerna (frontendbackend och listen sektioner) för att skicka meddelanden till syslog-servern (- erna) som är konfigurerade i avsnittet global. Detta görs genom att lägga till ett log global – direktiv. Du kan lägga till den i defaults sektionen, som visas:
log global direktivet säger i princip, använd log linje som sattes i global sektionen. Att sätta ettlog global – direktiv idefaults – avsnitt motsvarar att sätta det i alla efterföljande proxyavsnitt. Så det här gör det möjligt att logga in på alla proxyer. Du kan läsa mer om avsnitten i en HAProxy-konfigurationsfil i vårt blogginlägg de fyra väsentliga avsnitten i en HAProxy-konfiguration.
som standard är utdata från HAProxy minimal. Lägga till raden option httplog till din defaults avsnitt kommer att möjliggöra mer utförlig HTTP loggning, som vi kommer att förklara mer i detalj senare.
en typisk HAProxy-konfiguration ser ut så här:
att använda globala loggningsregler är den vanligaste HAProxy-inställningen, men du kan placera dem direkt i ett frontend avsnitt istället. Det kan vara användbart att ha en annan loggningskonfiguration som en engång. Du kanske till exempel vill peka på en annan Målsyslog-server, använda en annan loggningsanläggning eller fånga olika svårighetsgrader beroende på användningsfallet för backend-programmet. Tänk på följande exempel därfrontend sektioner, fe_site1 och fe_site2, ställer in olika IP-adresser och svårighetsgrader:
När du loggar till en lokal Syslog-tjänst kan skrivning till ett UNIX-uttag vara snabbare än att rikta in TCP-loopback-adressen. I allmänhet, på Linux-system, är ett UNIX-uttag som lyssnar på Syslog-meddelanden tillgängligt på /dev/log eftersom det är här syslog () – funktionen i GNU C-biblioteket skickar meddelanden som standard. Rikta UNIX-uttaget så här:
Du bör dock komma ihåg att om du ska använda ett UNIX—uttag för loggning och samtidigt kör HAProxy i en chrooted miljö—eller du låter HAProxy skapa en chroot katalog för dig genom att använda chroot configuration directive-då måste UNIX-uttaget göras tillgängligt i den chroot-katalogen. Detta kan göras på ett av två sätt.
först när rsyslog startar kan det skapa ett nytt lyssningsuttag i chroot-filsystemet. Lägg till följande i din HAProxy rsyslog-konfigurationsfil:
det andra sättet är att manuellt lägga till uttaget i chroot-filsystemet genom att använda kommandot mount med alternativet --bind.
var noga med att lägga till en post i din/etc / fstab-fil eller i en systemd-enhetsfil så att fästet kvarstår efter en omstart. När du har loggat konfigurerat vill du förstå hur meddelandena är strukturerade. I nästa avsnitt ser du fälten som utgör TCP-och HTTP-nivåloggarna.
om du behöver begränsa mängden data som lagras är ett sätt att bara prova en del loggmeddelanden. Ställ in loggnivån till tyst för ett slumpmässigt antal förfrågningar, så här:
Observera att om möjligt är det bättre att fånga så mycket data som möjligt. På så sätt saknar du inte information när du behöver det mest. Du kan också ändra ACL-uttrycket så att vissa villkor åsidosätter regeln.
ett annat sätt att begränsa antalet loggade meddelanden är att ställa in option dontlog-normal I ditt defaults eller frontend. På så sätt fångas bara timeouts, försök och fel. Du skulle förmodligen inte vilja aktivera detta hela tiden, men bara under vissa tider, till exempel när du utför benchmarking-tester.
Om du kör HAProxy inuti en Docker-behållare och du använder HAProxy version 1.9, kan du istället för att skicka loggutmatning till en Syslog-server skicka den till stdout och/eller stderr. Ställ in adressen till stdouteller stderr. I så fall är det också att föredra att ställa in meddelandets format till raw, så här:
HAProxy loggformat
den typ av loggning du ser bestäms av proxy-läget som du ställer in i HAProxy. HAProxy kan fungera antingen som en Layer 4 (TCP) proxy eller som Layer 7 (HTTP) proxy. TCP-läge är standard. I det här läget upprättas en fullduplexanslutning mellan klienter och servrar, och ingen layer 7-undersökning kommer att utföras. Om du har ställt in din rsyslog-konfiguration baserat på vår diskussion i det första avsnittet hittar du loggfilen på /var/log/haproxy-traffic.logga.
När du är i TCP-läge, som ställs in genom att lägga till mode tcp, bör du också lägga till alternativ tcplog. Med det här alternativet är loggformatet som standard en struktur som ger användbar information som Layer 4-anslutningsdetaljer, timers, byte count, etc. Om du skulle återskapa detta format med log-format, som används för att ställa in ett anpassat format, skulle det se ut så här:
beskrivningar av dessa fält finns i dokumentationen för TCP-loggformat, även om vi beskriver flera i det kommande avsnittet.
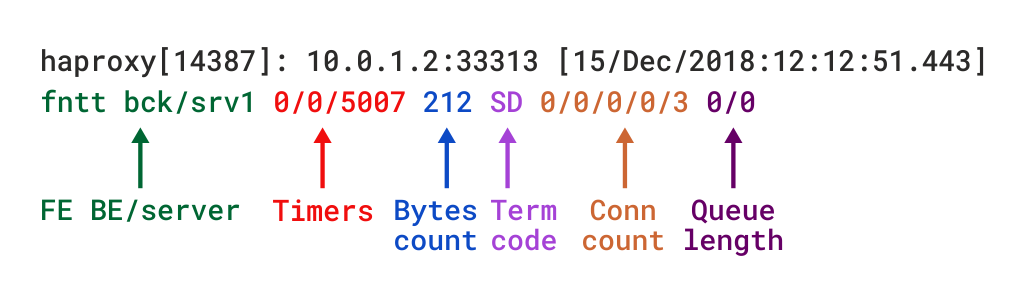
tcp loggformat i HAProxy
När HAProxy körs som ett lager 7 proxy via mode http, bör du lägga till alternativet httplog direktivet. Det säkerställer att HTTP-förfrågningar och svar analyseras på djupet och att inget RFC-kompatibelt innehåll kommer att fångas upp. Detta är det läge som verkligen belyser det diagnostiska värdet av HAProxy. HTTP-loggformatet ger samma informationsnivå som TCP-formatet, men med ytterligare data som är specifika för HTTP-protokollet. Om du skulle återskapa detta format med log-format, skulle det se ut så här:
detaljerade beskrivningar av de olika fälten finns i HTTP-loggformatdokumentationen.
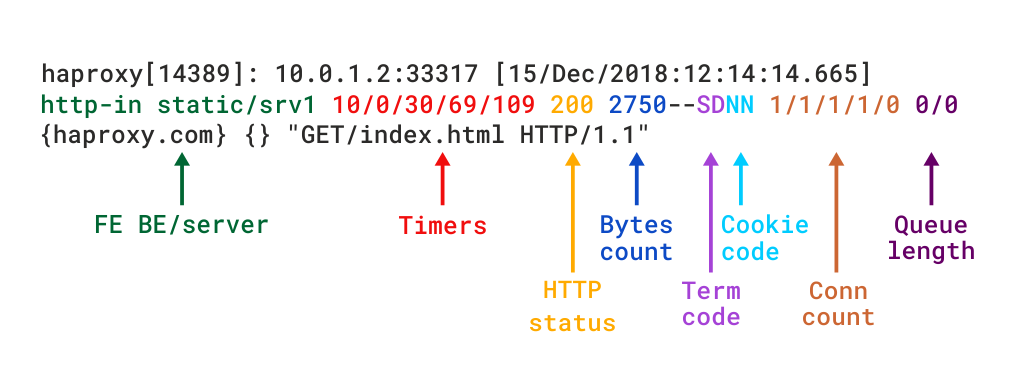
HTTP log format i HAProxy
Du kan också definiera en anpassad log format, fånga bara vad du behöver. Använd log-format (eller log-format-sd för structured-data syslog) – direktivet i ditt defaults eller frontend. Läs vårt blogginlägg HAProxy Log anpassning att lära sig mer och se några exempel.
i de närmaste avsnitten kommer du att bli bekant med de fält som ingår när du använder option tcplog eller option httplog.
Proxies
i loggfilen som produceras börjar varje rad med frontend, backend och server som begäran skickades till. Om du till exempel hade följande HAProxy-konfiguration skulle du se rader som beskriver förfrågningar som dirigerade via http-in frontend till den statiska backend och sedan till srv1-servern.
detta blir viktig information när du behöver veta var en begäran skickades, till exempel när du ser fel som bara påverkar några av dina servrar.
Timers
Timers tillhandahålls i millisekunder och täcker händelserna som händer under en session. Timers som fångas av standard TCP-loggformat är Tw / Tc / Tt. De som tillhandahålls av standard HTTP-loggformat är TR/ Tw / Tc / Tr / Ta. Dessa översätter som:
| Timer | vilket betyder |
| tr | den totala tiden för att få klientförfrågan (endast HTTP-läge). |
| Tw | den totala tiden i köerna som väntar på en anslutningsplats. |
| Tc | den totala tiden för att upprätta TCP-anslutningen till servern. |
| tr | serverns svarstid (endast HTTP-läge). |
| Ta | den totala aktiva tiden för HTTP-begäran (endast HTTP-läge). |
| Tt | den totala TCP-sessionens varaktighet, mellan det ögonblick som proxyn accepterade det och det ögonblick som båda ändarna stängdes. |
Du hittar en detaljerad beskrivning av alla tillgängliga timers i HAProxy-dokumentationen. Följande diagram visar också var tiden registreras under en enda end-to-end-transaktion. Observera att de lila linjerna på kanterna betecknar timers.
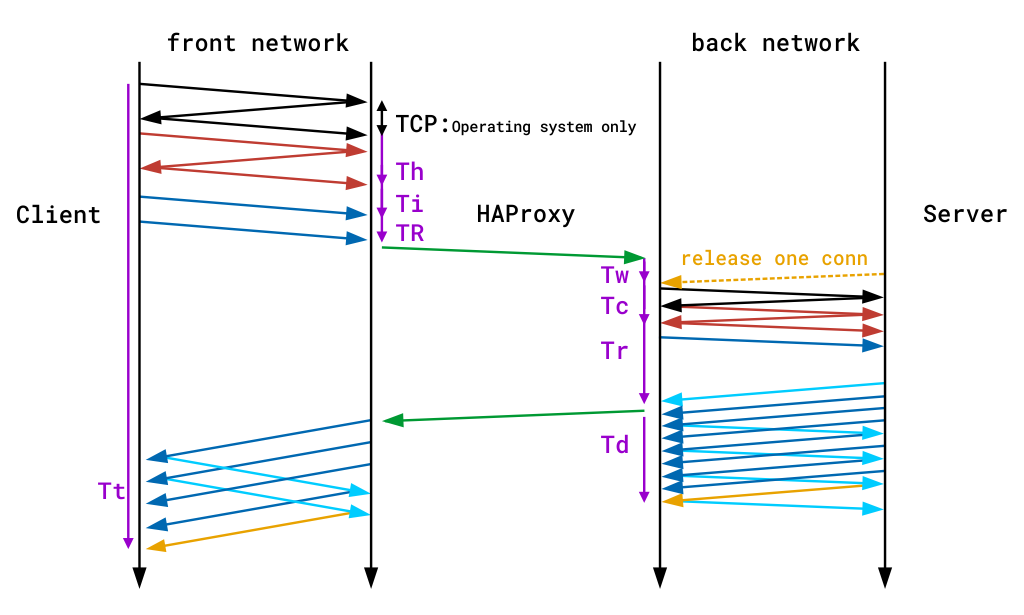
time recording under en enda end-to-end-transaktion
sessionsstatus vid frånkoppling
både TCP-och HTTP-loggar innehåller en avslutningskod som anger hur TCP-eller HTTP-sessionen slutade. Det är en kod med två tecken. Det första tecknet rapporterar den första händelsen som orsakade att sessionen avslutades, medan det andra rapporterar TCP-eller HTTP-sessionstillståndet när den stängdes.
här är några exempel på termineringskod:
| två tecken kod | betydelse |
| – | Normal uppsägning på båda sidor. |
| cD | klienten skickade inte eller bekräftade några data och så småningom timeout client gick ut. |
| SC | servern vägrade uttryckligen TCP-anslutningen. |
| PC | proxyn vägrade att upprätta en anslutning till servern eftersom processens uttagsgräns uppnåddes när man försökte ansluta. |
det finns en mängd olika anledningar till att en anslutning kan ha stängts. Detaljerad information om alla möjliga termineringskoder finns i HAProxy-dokumentationen.
räknare
räknare anger systemets hälsa när en begäran gick igenom. HAProxy registrerar fem räknare för varje anslutning eller begäran. De kan vara ovärderliga för att bestämma hur mycket belastning som placeras på systemet, där systemet släpar och om gränser har träffats. När du tittar på en rad i loggen ser du räknarna listade som fem siffror åtskilda av snedstreck: 0/0/0/0/0.
i antingen TCP-eller HTTP-läge bryts dessa ner som:
- det totala antalet samtidiga anslutningar på Haproxyprocessen när sessionen loggades.
- det totala antalet samtidiga anslutningar som dirigeras genom detta
frontendnär sessionen loggades. - det totala antalet samtidiga anslutningar som dirigeras till detta
backendnär sessionen loggades. - det totala antalet samtidiga anslutningar som fortfarande är aktiva på detta
servernär sessionen loggades. - antalet försök som gjorts när du försöker ansluta till backend-servern.
andra fält
HAProxy spelar inte in allt out-of-the-box, men du kan justera det för att fånga vad du behöver. En HTTP-förfrågningshuvud kan loggas genom att lägga tillhttp-request capture – direktivet:
loggen visar rubriker mellan lockiga hängslen och åtskilda av rörsymboler. Här kan du se värd-och Användaragentrubrikerna för en begäran:
ett svarshuvud kan loggas genom att lägga till ett http-response capture direktiv:
i det här fallet måste du också lägga till ett declare capture response direktiv, som allokerar en infångningsplats där svarshuvudet, när det kommer, kan lagras. Varje kortplats som du lägger till tilldelas automatiskt ett ID som börjar från noll. Referera till detta ID när du ringer http-response capture. Svarhuvuden loggas efter förfrågningshuvudena, inom en separat uppsättning lockiga hängslen.
Cookievärden kan loggas på liknande sätt med http-request capture direktivet.
allt som fångas med http-request capture, inklusive HTTP-rubriker och cookies, kommer att visas inom samma uppsättning lockiga hängslen. Detsamma gäller för allt som fångats med http-response capture.
Du kan också använda http-request capture för att logga samplade data från sticktabeller. Om du spårade användarförfrågningsfrekvenser med ett stick-table kan du logga dem så här:
så att göra en begäran till en webbsida som innehåller HTML-dokumentet och två bilder skulle visa användarens samtidiga begärningshastighet som ökar till tre:
Du kan också logga värdena för hämtningsmetoder, till exempel för att spela in versionen av SSL/TLS som användes (Observera att det finns en inbyggd loggvariabel för att få detta kallat %sslv):
variabler med http-request set-var kan också loggas.
ACL-uttryck utvärderas till antingen sant eller falskt. Du kan inte logga dem direkt, men du kan ställa in en variabel baserat på om uttrycket är sant. Om användaren till exempel besöker /api kan du ställa in en variabel som heter req.is_api till ett värde av Is API och sedan fånga det i loggarna.
aktivera HAProxy profilering
med utgåvan av HAProxy 1.9 kan du spela in CPU-tid som spenderas på att behandla en begäran inom HAProxy. Lägg till profiling.tasks – direktivet till ditt global avsnitt:
det finns nya hämtningsmetoder som exponerar profileringsmåtten:
| hämta metod | beskrivning |
date_us |
mikrosekunder delen av datumet. |
cpu_calls |
antalet samtal till uppgiften som behandlar strömmen eller aktuell begäran sedan den tilldelades. Det återställs för varje ny begäran på samma anslutning. |
cpu_ns_avg |
det genomsnittliga antalet nanosekunder som spenderas i varje samtal till uppgiften som behandlar strömmen eller aktuell begäran. |
cpu_ns_tot |
det totala antalet nanosekunder som spenderas i varje samtal till uppgiften som behandlar strömmen eller aktuell begäran. |
lat_ns_avg |
det genomsnittliga antalet nanosekunder som spenderas mellan det ögonblick som uppgiftshanteringen av strömmen vaknar och det ögonblick det effektivt kallas. |
lat_ns_tot |
det totala antalet nanosekunder mellan det ögonblick som uppgiften hanterar strömmen vaknar och det ögonblick det effektivt kallas. |
Lägg till dessa i dina loggmeddelanden så här:
detta är ett bra sätt att mäta vilka förfrågningar som kostar mest att bearbeta.
Parsing HAProxy Logs
som du har lärt dig har HAProxy många fält som ger en enorm insikt om anslutningar och förfrågningar. Att läsa dem direkt kan dock leda till överbelastning av information. Ofta är det lättare att analysera och aggregera dem med externa verktyg. I det här avsnittet ser du några av dessa verktyg och hur de kan utnyttja loggningsinformationen från HAProxy.
HALog
HALog är ett litet men kraftfullt logganalysverktyg som levereras med HAProxy. Det var utformat för att distribueras på produktionsservrar där det kan hjälpa till med manuell felsökning, till exempel när man står inför liveproblem. Det är extremt snabbt och kan analysera TCP-och HTTP-loggar med 1 till 2 GB per sekund. Genom att skicka en kombination av flaggor kan du extrahera statistisk information från loggarna, inklusive förfrågningar per URL och förfrågningar per källa IP. Sedan kan du sortera efter svarstid, felfrekvens och avslutningskod.
om du till exempel vill extrahera statistik per server från loggarna kan du använda följande kommando:
detta är användbart när du behöver analysera loggrader per statuskod och snabbt upptäcka om en viss server är ohälsosam (t.ex. returnerar för många 5xx-svar). Eller en server kan förneka för många förfrågningar (4xx-svar), vilket är ett tecken på en brute-force-attack. Du kan också få den genomsnittliga svarstiden per server med kolumnen avg_rt, vilket är användbart för felsökning.
med HALog kan du få statistik per URL genom att använda följande kommando:
utgången visar antalet förfrågningar, antalet fel, den totala beräkningstiden, den genomsnittliga beräkningstiden, den totala beräkningstiden för framgångsrika förfrågningar, den genomsnittliga beräkningstiden för framgångsrika förfrågningar, det genomsnittliga antalet skickade byte och det totala antalet skickade byte. Förutom att analysera server-och URL-statistik kan du använda flera filter för att matcha loggar med en viss svarstid, HTTP-statuskod, sessionsavslutningskod etc.
HAProxy Stats Page
att analysera loggarna med HALog är inte det enda sättet att få mätvärden ur HAProxy. HAProxy-statistiksidan kan aktiveras genom att lägga tillstats enable – direktivet till ettfrontend ellerlisten avsnitt. Den visar levande statistik över dina servrar. Avsnittet followlisten startar statistiksidan lyssna på port 8404:
statistiksidan är mycket användbar för att få omedelbar information om trafiken som flyter genom HAProxy. Det lagrar dock inte dessa data och visar endast data för en enda belastningsbalans.
HAProxy Enterprise Real-Time Dashboard
Om du använder HAProxy Enterprise har du tillgång till Real-Time Dashboard. Medan statistiksidan visar statistik för en enda instans av HAProxy, samlar instrumentpanelen i realtid och visar information över ett kluster av lastbalanserare. Detta gör det enkelt att observera hälsan hos alla dina servrar från en enda skärm. Data kan ses i upp till 30 minuter.
instrumentpanelen lagrar och visar information om tjänstens hälsa, begär priser och belastning. Det gör det också lättare att utföra administrativa uppgifter, som att aktivera, inaktivera och tömma backends. I en överblick kan du se vilka servrar som är uppe och hur länge. Du kan också visa stick-tabelldata, som, beroende på vad stick-tabellen spårar, kan visa felfrekvenser, begärningsfrekvenser och annan realtidsinformation om dina användare. Stick tabelldata kan också aggregeras.
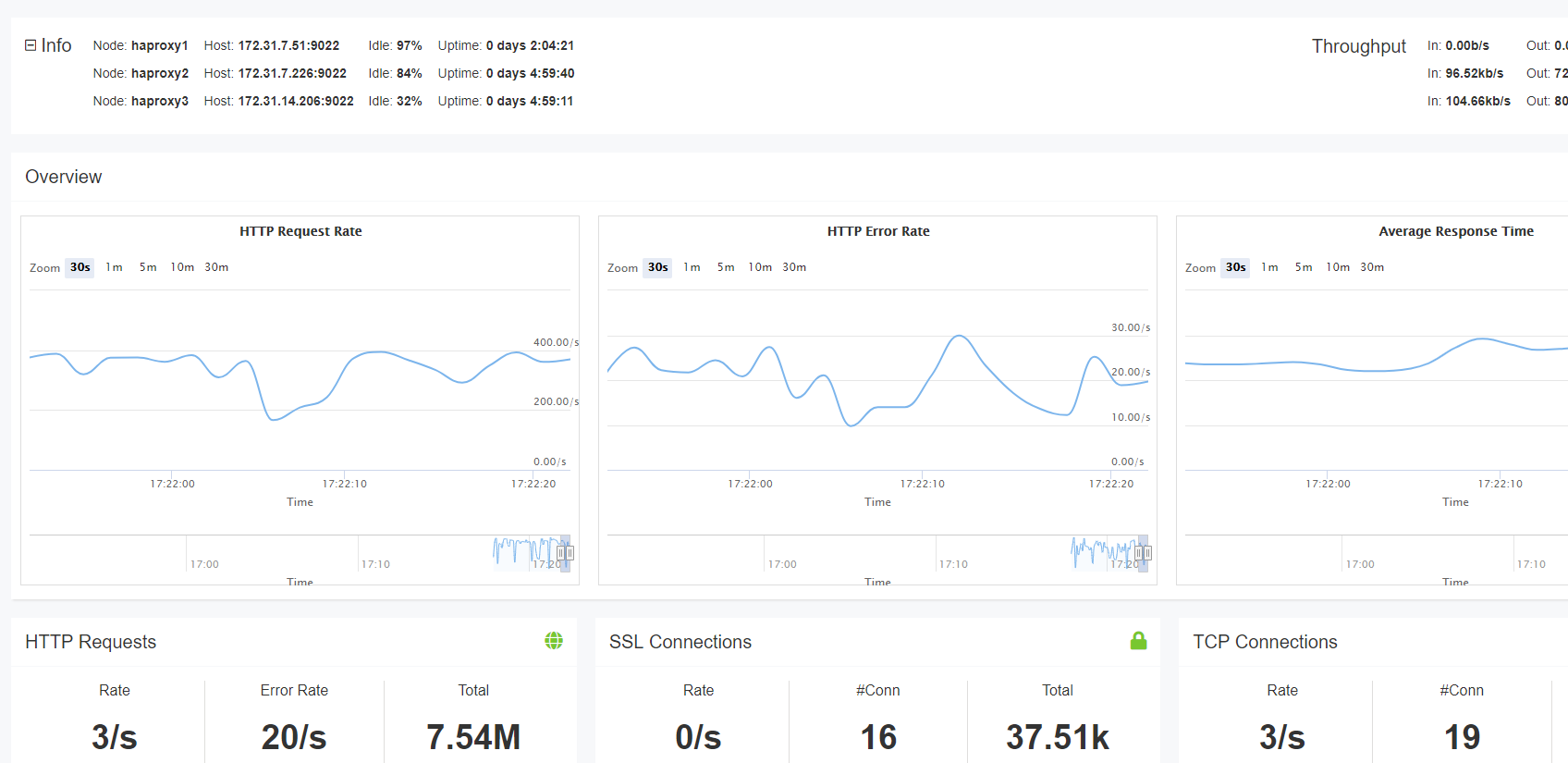
real-Time Dashboard i HAProxy Enterprise
Real-Time Dashboard är ett av många tillägg tillgängliga med HAProxy Enterprise.
slutsats
i det här blogginlägget lärde du dig hur du konfigurerar HAProxy-loggning för att få observerbarhet över din lastbalanserare, vilket är en kritisk komponent i din Infrastruktur. HAProxy avger detaljerade Syslog-meddelanden när du arbetar i antingen TCP – och HTTP-läge. Dessa kan skickas till ett antal loggningsverktyg, till exempel rsyslog.
HAProxy levereras med kommandoradsverktyget HALog, vilket förenklar tolkning av loggdata när du behöver information om vilka typer av svar användarna får och belastningen på dina servrar. Du kan också få en visuell av hälsan hos dina servrar med hjälp av HAProxy statistik sida eller HAProxy Enterprise realtid instrumentpanelen.
vill du veta när innehåll som detta publiceras? Prenumerera på den här bloggen eller följ oss på Twitter. Du kan också delta i konversationen på Slack! HAProxy Enterprise kombinerar HAProxy med funktioner i företagsklass, till exempel instrumentpanelen i realtid och premiumsupport. Kontakta oss för att lära dig mer eller registrera dig för en GRATIS Provperiod idag!