
올 때 operationalizing 로그 데이터,류 운영체제에 대 풍부한 정보를 제공한다. 이 블로그 게시물에서는 하프록시 로깅을 설정하고,시스템 로그 서버를 타겟팅하고,로그 필드를 이해하고,로그 파일을 구문 분석하는 데 유용한 도구를 제안하는 방법을 보여 줍니다. 해 프록시는 인프라의 중요한 경로에 앉아있다. 에지 로드 밸런서,사이드카 또는 쿠버네티스 인그레스 컨트롤러로 사용하든,하프록시에서 의미 있는 로그를 얻는 것은 필수적이다.로깅은 각 연결 및 요청에 대한 통찰력을 제공합니다. 문제 해결에 필요한 관찰 가능성을 가능하게하고 문제를 조기에 감지하는 데 사용할 수도 있습니다. 그것은 하프록시에서 정보를 얻을 수있는 여러 가지 방법 중 하나입니다. 다른 방법으로는 통계 페이지를 사용하여 메트릭을 얻고,이메일 알림을 설정하고,시간이 지남에 따라 로그 또는 통계 데이터를 저장하기 위해 다양한 오픈 소스 통합을 사용하는 방법이 있습니다. 하프록시는 밀리초 정확도로 매우 상세한 로그를 제공하고 인프라에 흐르는 트래픽에 대한 풍부한 정보를 생성합니다. 트래픽에 대한 메트릭:타이밍 데이터,연결 카운터,트래픽 크기 등 정보:콘텐츠 전환,필터링,지속성 등 요청 및 응답에 대한 정보:헤더,상태 코드,페이로드 등 세션 종료 상태 및 오류가 발생하는 위치를 추적 할 수있는 능력(클라이언트 측,서버 측?이 게시물에서는 하프록시 로깅을 구성하는 방법과 생성하는 로그 메시지를 읽는 방법을 배웁니다. 그런 다음 로그 데이터를 운영할 때 도움이 되는 몇 가지 도구를 나열합니다.시스템 로그 서버에 의해 처리될 로그 메시지를 내보낼 수 있습니다. 이것은 수학적으로 정확한 유형 계층구조인,강력한 타입을 정의합니다. 이것은 수학적으로 정확한 유형 계층구조인,강력한 타입을 정의합니다.이 패키지에는 디버깅 심볼이 들어 있습니다. 이 경우,당신은 방법을 볼 수 있습니다 다음 섹션으로 건너 뜁니다.예를 들어,사용자가 로그에 로그인할 때 로그가 생성될 때 로그가 생성될 때 로그가 생성될 때 로그가 생성될 때 로그가 생성될 때 로그가 생성될 때 로그가 생성될 때 로그가 생성될 때 로그가 생성될 때 로그가 생성될 때 로그가 생성될 때 로그가 생성될 때 로그가 생성될 때 로그가 생성될 때 로그가 생성될 때 로그가 생성될 때 로그가 생성될 때 로그가 생성될 이 툴의 목적은 웹사이트를 사용하기 쉽게 하고,오류 상황을 선행적으로 인지하고 수정하게 하려는 것입니다. 다음 중 하나를 추가/기타/아르 자형 로그.또는 새 파일로 이동합니다.이 디렉토리는 다음과 같습니다.디/하프록시.그런 다음 서비스를 다시 시작하십시오. 루프백 주소(127.0.0.1)에서 수신 대기합니다. 이 특정 구성은 두 개의 로그 파일에 씁니다. 선택한 파일은 메시지가 기록된 심각도 수준을 기반으로 합니다. 이를 이해하려면 파일의 마지막 두 줄을 자세히 살펴보십시오. 그들은 다음과 같이 시작합니다:시스템 로그 표준은 기록된 각 메시지에 시설 코드 및 심각도 수준을 할당하도록 규정합니다. 이 예제에서는 모든 로그 메시지를 로컬 0 의 기능 코드로 보내도록 하프록시를 구성한다고 가정할 수 있습니다.심각도 수준은 시설 코드 뒤에 점으로 구분되어 지정됩니다. 여기서 첫 번째 줄은 모든 심각도 수준에서 메시지를 캡처하여 하프록시 트래픽이라는 파일에 기록합니다.로그. 두 번째 줄은 위의 통지 수준 메시지 만 캡처하여 하 프록시라는 파일에 로깅합니다.로그.특정 메시지를 보낼 때 특정 심각도 수준을 사용하도록 하드 코딩됩니다. 예를 들어 연결 및
| 정도 수준 | 류 운영체제에 대 Logs |
| emerg | 같은 오류가의 실행하는 운영 시스템 파일기술자.이러한 응답을 캐시 할 수없는 것으로,예기치 않은 일이 일어난 일부 드문 경우.이 문제를 해결하려면 다음을 수행하십시오.맵 파일을 구문 분석할 수 없거나,해프록시 구성 파일을 구문 분석할 수 없거나,스틱 테이블에 대한 작업이 실패할 때와 같은 오류입니다.요청 헤더를 설정하지 못하거나 네임 서버에 연결하지 못하는 등의 중요하지만 중요하지 않은 오류가 있습니다.위 또는 아래 또는 서버가 비활성화된 경우와 같이 서버 상태가 변경됩니다. 시작 시 프록시 시작 및 모듈 로딩과 같은 다른 이벤트도 포함되어 있습니다. 상태 검사 로깅이 활성화된 경우 이 수준도 사용합니다.이 문제를 해결하려면 다음 단계를 수행하십시오. |
| 디버깅 | 할 수 있습 쓰기 사용자 지정 Lua 코드를 기록하는 디버그 메시지 |
현대적인 리눅스 배포판은 제공된 서비스 관리자 systemd 소개 journald 에 대한 수집하고 저장하는 로그입니다. 저널릴드 서비스는 시스템 로그 구현이 아니지만,동일한/개발/로그 소켓에서 수신되기 때문에 시스템 로그와 호환됩니다. 수신 된 로그를 수집하고 사용자가 동등한 저널링 필드(시스템 로그 _특성,우선 순위)를 사용하여 시설 코드 및/또는 심각도 수준별로 필터링 할 수 있도록합니다.
류 운영체제에 대 Logging Configuration
류 운영체제에 대 설정 매뉴얼 다운로드를 설명하는 로깅을 사용하도록 설정할 수 있습을 가진 두 개의 단계:최초 지정하는 것입 Syslog servergloballog지시어를 사용:
log지시어는 지시한류 운영체제에 대해 로그를 보내 Syslog server 듣기에 127.0.0.1:514. 이 메시지는 표준 사용자 정의 시스템 로그 기능 중 하나입니다. 그것은 또한 우리의 알시 로그 구성이 기대하는 시설이다. 두 개 이상의 명령문을 추가하여 여러 시스템 로그 서버에 출력을 보낼 수 있습니다.
는 방법을 제어할 수 있습니다 많은 정보가 로그에 추가하여 Syslog 수준의 끝 라인:
두 번째 단계를 구성하는 로깅 사이트를 이용하려는 다른 프록시(frontendbackend,andlisten섹션)위에 메시지를 보내는 Syslog server(s) 에서 구성globallog globaldefaults섹션에 해당하는 퍼팅 그것으로 모든 의 후속 프록시의 섹션이 있습니다. 그래서,이 모든 프록시에서 로깅을 가능하게 할 것이다. 당신은 우리의 블로그 게시물에서 해프록시 구성 파일의 섹션에 대한 자세한 내용을보실 수 있습니다 해프록시 구성의 네 가지 필수 섹션.이 경우 출력이 최소화됩니다. 이 섹션에서는 더 자세한 웹 로깅 기능을 사용할 수 있으며 나중에 더 자세히 설명합니다.전역 로깅 규칙을 사용하는 것이 가장 일반적인 해프록시 설정입니다. 다른 로깅 구성을 일회성으로 사용하는 것이 유용할 수 있습니다. 예를 들어 다른 대상 시스템 로그 서버를 가리키거나 다른 로깅 기능을 사용하거나 백엔드 응용 프로그램의 사용 사례에 따라 다른 심각도 수준을 캡처할 수 있습니다. 로컬 시스템 로그 서비스에 로깅할 때 유닉스 소켓에 쓰는 것이 루프백 주소를 대상으로 하는 것보다 빠를 수 있습니다. 일반적으로 리눅스 시스템에서는 유닉스 소켓에서 시스템 로그 메시지를 수신하고 있습니다. 그러나 로깅을 위해 유닉스 소켓을 사용하고 동시에 크로트된 환경 내에서 하프록시를 실행하는 경우- 이것은 두 가지 방법 중 하나로 수행 할 수 있습니다.먼저,알시로그가 시작될 때,그것은 치루트 파일 시스템 내에 새로운 청취 소켓을 만들 수 있다. 에 다음을 추가 귀하의류 운영체제에 대그램 구성 파일:
두 번째 방법은 수동으로 추가의 소켓을 chroot 파일 시스템을 사용하여mount--bind옵션을 선택합니다.다시 부팅한 후에도 마운트가 유지되도록 항목을 추가해야 합니다. 로깅을 구성한 후에는 메시지가 어떻게 구성되는지 이해해야 합니다. 다음 섹션에서는
다른 방법으로 메시지 수를 제한 로그인을 설정하는 것입option dontlog-normaldefaultsfrontendraw아래와 같이
류 운영체제에 대한 로그 형식
로깅 유형은 당신이 볼 수에 의해 결정된 프록시 모드를 설정에서류 운영체제에 대. 이 프록시는 계층 4 또는 계층 7 프록시로 작동 할 수 있습니다. 이 모드는 기본 모드입니다. 이 모드에서는 클라이언트와 서버 간에 전이중 연결이 설정되며 계층 7 검사는 수행되지 않습니다. 첫 번째 섹션에서 논의한 내용을 토대로 로그 구성을 설정했다면 로그 파일을 찾을 수 있습니다.로그.이 경우,당신은 또한 옵션을 추가 할 수 있습니다. 이 옵션을 사용하면 로그 형식이 레이어 4 연결 세부 정보,타이머,바이트 수 등과 같은 유용한 정보를 제공하는 구조로 기본 설정됩니다. 이 형식은 사용자 지정 형식을 설정하는 데 사용됩니다.:이 필드에 대한 설명은 다음 섹션에서 몇 가지를 설명하지만 로그 형식 문서에서 찾을 수 있습니다.
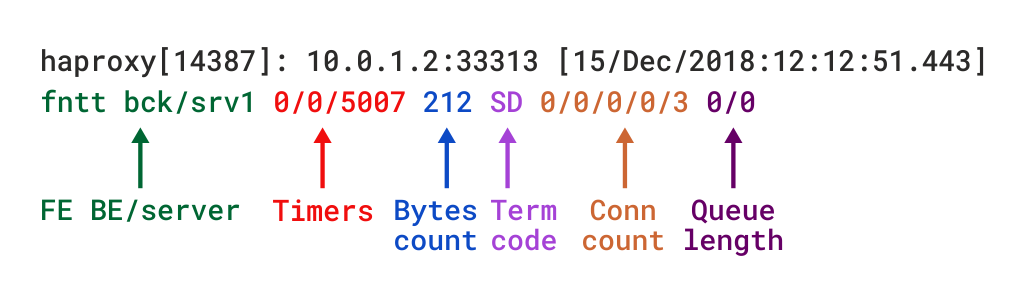
TCP 로그 형식에서류 운영체제에 대
때류 운영체제에 대으로 실행 7 계층 프록시를 통해mode http,당신은 옵션을 추가 httplog directive. 이 프로그램은 모듈식 구조,유연한 구조,그리고 외부 데이터 베이스와는 독립적으로 구동할 수 있도록 설계되었습니다. 이 모드는 하프록시의 진단 값을 실제로 강조하는 모드입니다. 이 예제에서는 다음과 같이 설명합니다. 다른 필드에 대한 자세한 설명은
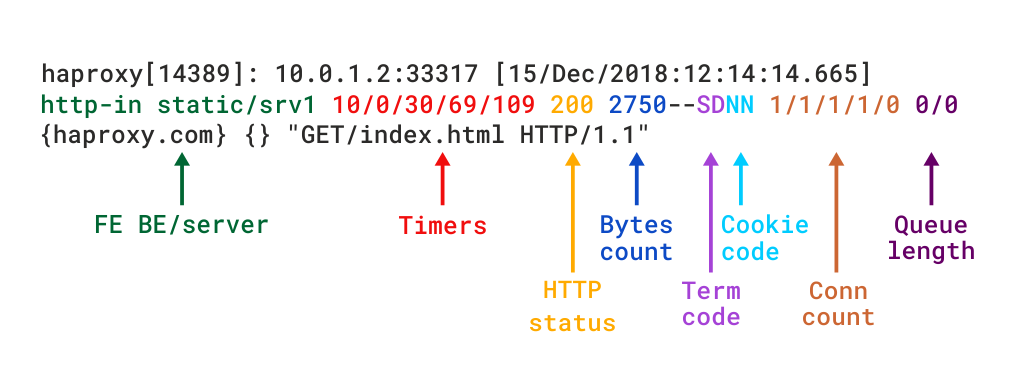
HTTP 로그 형식에서류 운영체제에 대
정의할 수도 있습니다 사용자 지정한 로그 형식을 캡처,만 당신이 필요합니다. 이 명령어는 시스템 로그의 구조화 된 데이터 로그에 대한 명령어를 사용하여 데이터 로그의 구조화 된 데이터 로그에 대한 명령어를 사용합니다. 우리의 블로그 게시물 읽기 해 프록시의 로그 사용자 정의 자세히보기 및 몇 가지 예를 참조하십시오.다음 몇 절에서,당신은 당신이 사용할 때 포함 된 필드에 익숙해 질 수 있습니다생성된 로그 파일 내에서 각 줄은 요청이 전송된 프런트 엔드,백엔드 및 서버로 시작합니다. 예를 들어 다음과 같은 구성을 사용하는 경우 요청을 정적 백엔드로 라우트한 다음 정적 백엔드로 라우트하는 것으로 설명하는 줄을 볼 수 있습니다.이 정보는 일부 서버에만 영향을 미치는 오류를 볼 때와 같이 요청이 전송 된 위치를 알아야 할 때 중요한 정보가됩니다.타이머는 밀리 초 단위로 제공되며 세션 중에 발생하는 이벤트를 다룹니다. 기본 로그 형식으로 캡처된 타이머는 다음과 같습니다. 기본 로그 형식에서 제공하는 것은 다음과 같습니다. 이러한 번역으로.
| 타이머 | 의미 |
| TR | 총 시간을 얻을하는 클라이언트 요청(HTTP 모드만 해당).연결 슬롯을 기다리는 대기열에서 소요된 총 시간입니다.서버 연결을 설정하는 데 걸리는 총 시간입니다.서버 응답 시간(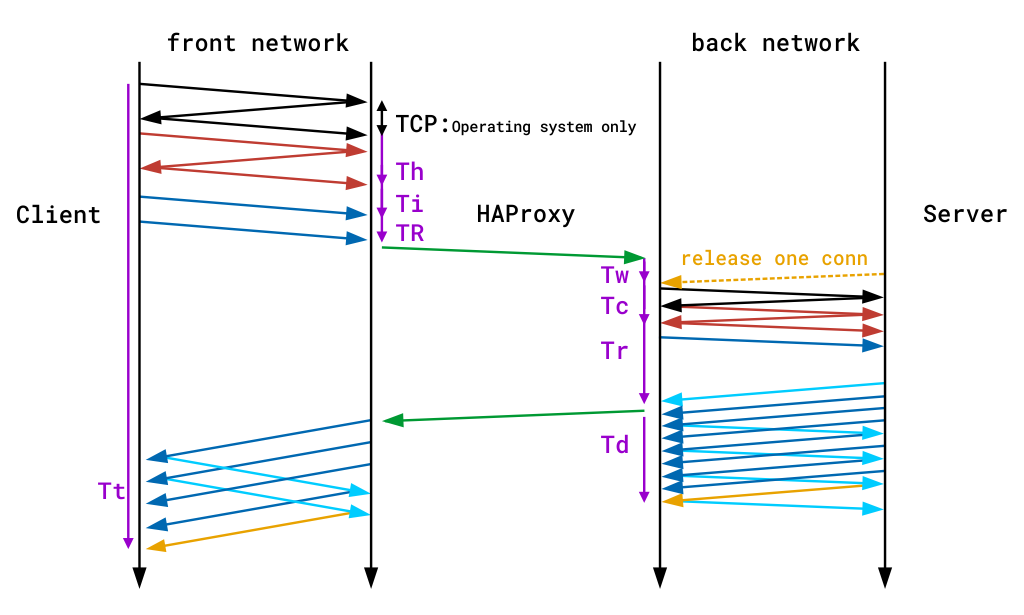
간 기록 중에 하나의 엔드-투-엔드 트랜잭션 세션 상태에서 연결 끊기TCP,HTTP 로그에는 다음 항목이 포함됩니다 종료 상태 코드를 사용하여 제한없이 사용할 수 있는 방법에는 TCP 또는 HTTP 세션이 끝났다. 그것은 두 문자 코드입니다. 첫 번째 문자는 세션이 종료된 첫 번째 이벤트를 보고하고 두 번째 문자는 세션이 종료된 경우 세션 상태를 보고합니다.다음은 몇 가지 종료 코드 예제입니다:두 개의 문자 코드는 두 개의 문자 코드를 의미하고 두 개의 문자 코드를 의미하고 두 개의 문자 코드를 의미하고 두 개의 문자 코드를 의미하고 두 개의 문자 코드를 의미하고 두 개의 문자 코드를 의미하고 두 개의 문자 코드를 의미하고 두 개의 문자 코드를 의미하고 두 개의 문자 코드를 의미하고 두 개의 문자 코드를 의미하고 두 개의 문자 코드를 의미하고 두 개의 문자 코드를 의미하고 두 개의 문자 코드를 의미하고 두 개의 문자 코드를 의미하고 두 개의 문자 코드를클라이언트에서 데이터를 전송하거나 승인하지 않았으며 결국 만료되었습니다.이 문제를 해결하려면 다음을 수행하십시오.연결을 시도하는 동안 프로세스의 소켓 제한에 도달했기 때문에 프록시가 서버 연결을 거부했습니다. |
이의 다양한 이유로 연결할 수 있는 폐쇄되었다. 가능한 모든 종료 코드에 대한 자세한 정보는 해프록시 문서에서 찾을 수 있습니다.카운터는 요청이 진행되었을 때의 시스템 상태를 나타냅니다. 각 연결 또는 요청에 대해 5 개의 카운터를 기록합니다. 그들은 얼마나 많은 부하 시스템에 배치 되 고,시스템 지체,그리고 제한 적중 여부 결정에 귀중 한 수 있습니다. 로그 내에서 라인을 볼 때,당신은 슬래시로 구분 다섯 숫자로 나열 카운터를 볼 수 있습니다:0/0/0/0/0.세션이 기록될 때 하프록시 프로세스의 총 동시 연결 수입니다.세션이 기록되었을 때 이 경로를 통해 라우팅된 총 동시 연결 수입니다.세션이 기록될 때 라우팅된 총 동시 연결 수입니다.세션이 기록되었을 때 현재 활성 상태인 총 동시 연결 수입니다.백엔드 서버에 연결하려고 할 때 시도된 재시도 횟수입니다.그러나 당신은 당신이 필요로하는 것을 캡처하기 위해 그것을 조정할 수 있습니다. 로그는 중괄호 사이의 헤더를 표시하고 파이프 기호로 구분합니다. 여기에서 요청에 대한 호스트 및 사용자 에이전트 헤더를 볼 수 있습니다:
응답 헤더를 기록할 수 있습을 추가하여http-response capture지시어:
이 경우에도 추가해야 합니다declare capture response:
로그인할 수도 있습의 값을 가져 같은 방법을 레코드 버전을 SSL/TLS 를 사용된(주는 기능이 내장되어 있어에서 로그 변수에 대한 이 호출%sslv):
변수를 설정과 함께http-request set-var//////////////////////////////이 예제에서는 날짜의 마이크로세컨드 부분을 보여 줍니다.할당된 이후 스트림 또는 현재 요청을 처리하는 작업에 대한 호출 수입니다. 동일한 연결에 대한 각 새 요청에 대해 재설정됩니다.스트림 또는 현재 요청을 처리하는 작업에 대한 각 호출에 소요된 평균 나노초 수입니다.스트림 또는 현재 요청을 처리하는 작업에 대한 각 호출에 소요된 총 나노초 수입니다.스트림을 처리하는 작업이 깨어있는 순간과 효과적으로 호출되는 순간 사이에 소요되는 평균 나노초 수입니다.스트림을 처리하는 작업이 깨어있는 순간과 효과적으로 호출되는 순간 사이의 총 나노초 수입니다.
추가 이러한 귀하의 로그인이 같은 메시지:
좋은 방법이를 측정하는 요청이 가장 비용합니다.당신이 배운 것처럼,해 프록시는 연결 및 요청에 대한 통찰력의 엄청난 양을 제공하는 필드를 많이 가지고 있습니다. 그러나 직접 읽으면 정보 과부하가 발생할 수 있습니다. 종종 외부 도구를 사용하여 구문 분석하고 집계하는 것이 더 쉽습니다. 이 섹션에서는 이러한 도구 중 일부를 볼 수 있습니다 그리고 그들은 어떻게 하프록시에서 제공하는 로깅 정보를 활용할 수 있습니다.로그 분석 도구:로그 분석 도구:로그 분석 도구:로그 분석 도구:로그 분석 도구:로그 분석 도구:로그 분석 도구:로그 분석 도구:로그 분석 도구:로그 분석 도구:로그 분석 도구:로그 분석 도구:로그 분석 도구:로그 분석 도구:로그 분석 도구:로그 분석 도구:로그 분석 도구:로그 분석 도구:로그 분석 도구 그것은 이러한 라이브 문제에 직면 할 때와 같은 수동 문제 해결에 도움이 될 수 있습니다 프로덕션 서버에 배포 할 수 있도록 설계되었습니다. 그것은 매우 빠르고 초당 1~2 기가바이트에서
류 운영체제에 대한 통계 페이지
구문 분석하는 로그와 HALog 지 않을 얻을 수있는 유일한 방법 메트릭의류 운영체제에 대. 이 페이지에는 다음과 같은 내용이 포함될 수 있습니다.************* 그것은 당신의 서버의 실시간 통계를 표시합니다. 통계 페이지는 하프록시를 통해 흐르는 트래픽에 대한 즉각적인 정보를 얻는 데 매우 유용합니다. 하지만 이 데이터는 저장하지 않으며 단일 부하 분산 장치에 대한 데이터만 표시합니다.당신이 해프록시 기업을 사용하는 경우,당신은 실시간 대시 보드에 액세스 할 수 있습니다. 통계 페이지는 하프록시의 단일 인스턴스에 대한 통계를 보여 주는 반면,실시간 대시보드는 로드 밸런서 클러스터에 걸쳐 정보를 집계하고 표시합니다. 따라서 한 화면에서 모든 서버의 상태를 쉽게 관찰할 수 있습니다. 데이터는 최대 30 분 동안 볼 수 있습니다.대시 보드는 서비스 상태,요청 속도 및 부하에 대한 정보를 저장하고 표시합니다. 또한 백엔드 활성화,비활성화 및 배수와 같은 관리 작업을 쉽게 수행 할 수 있습니다. 한 눈에,당신은 최대 얼마나 오래있는 서버를 볼 수 있습니다. 스틱 테이블이 추적하는 내용에 따라 오류율,요청률 및 사용자에 대한 기타 실시간 정보가 표시될 수 있는 스틱 테이블 데이터를 볼 수도 있습니다. 스틱 테이블 데이터도 집계 할 수 있습니다.
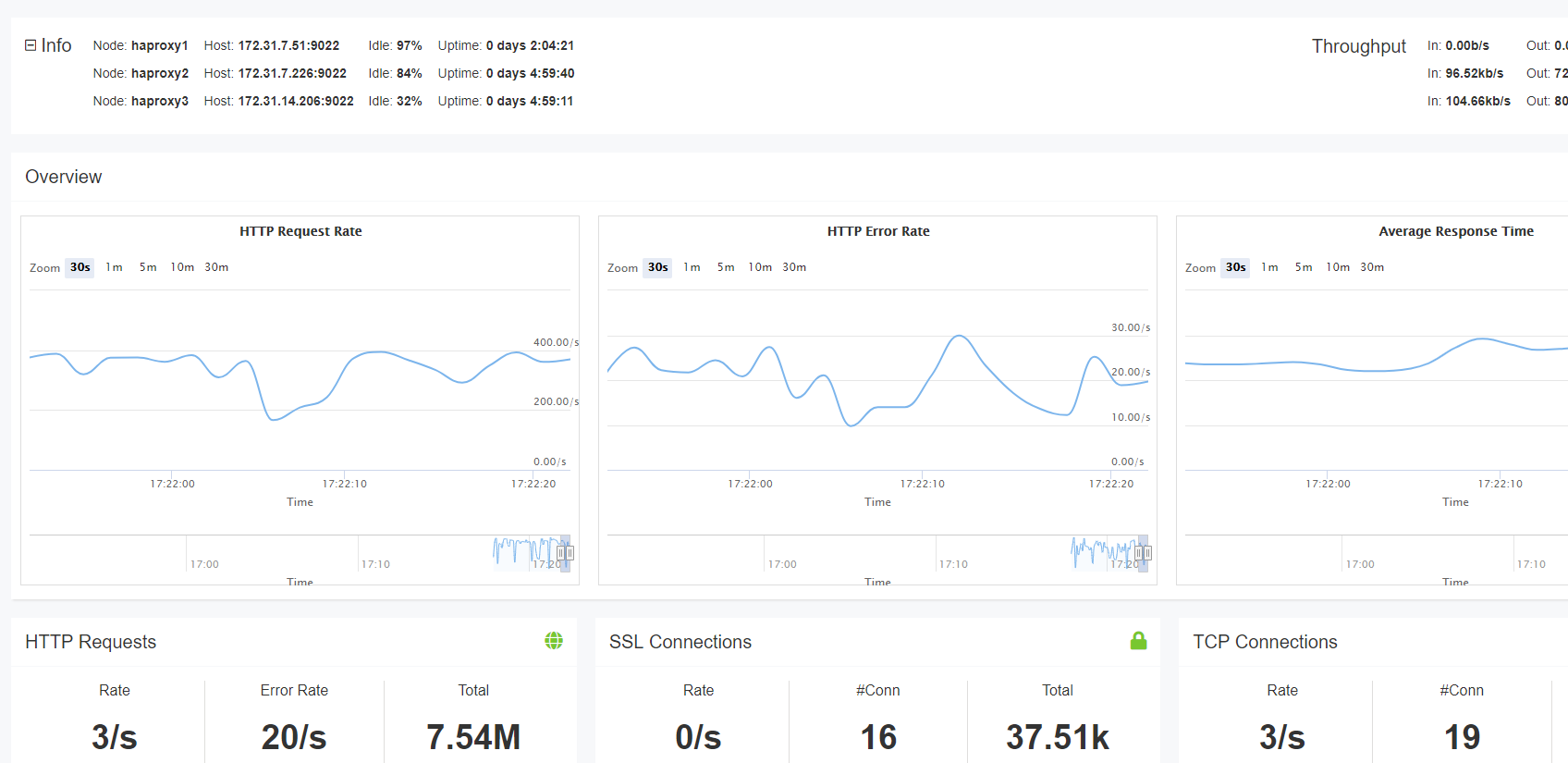
실시간 대시보드에서류 운영체제에 대 Enterprise
실시간 대시보드의 추가 기능을 사용할 수 있류 운영체제에 대 기업입니다.이 블로그 게시물에서는 인프라 내에서 중요한 구성 요소인 부하 분산 장치에 대한 관찰 가능성을 얻기 위해 하프록시 로깅을 구성하는 방법을 배웠습니다. 시스템 로그 메시지를 내보냅니다. 이 도구는