
Lorsqu’il s’agit d’opérationnaliser vos données de journal, HAProxy fournit une mine d’informations. Dans cet article de blog, nous expliquons comment configurer la journalisation HAProxy, cibler un serveur Syslog, comprendre les champs de journal et suggérer des outils utiles pour analyser les fichiers journaux.
Plongez dans la journalisation HAProxy
HAProxy se trouve dans le chemin critique de votre infrastructure. Qu’il soit utilisé comme équilibreur de charge périphérique, side-car ou comme contrôleur d’entrée Kubernetes, il est indispensable d’extraire des journaux significatifs de HAProxy.
La journalisation vous donne des informations sur chaque connexion et demande. Il permet l’observabilité nécessaire au dépannage et peut même être utilisé pour détecter les problèmes tôt. C’est l’une des nombreuses façons d’obtenir des informations de HAProxy. D’autres moyens incluent l’obtention de métriques à l’aide de la page de statistiques ou de l’API d’exécution, la configuration d’alertes par e-mail et l’utilisation des différentes intégrations open source pour stocker des données de journal ou statistiques au fil du temps. HAProxy fournit des journaux très détaillés avec une précision d’une milliseconde et génère une mine d’informations sur le trafic circulant dans votre infrastructure. Cela inclut :
- Métriques sur le trafic : données de synchronisation, compteurs de connexions, taille du trafic, etc.
- Informations sur les décisions HAProxy: commutation de contenu, filtrage, persistance, etc.
- Informations sur les demandes et les réponses : en-têtes, codes d’état, charges utiles, etc.
- Statut de terminaison d’une session et possibilité de suivre les pannes (côté client, côté serveur ?)
Dans cet article, vous apprendrez à configurer la journalisation HAProxy et à lire les messages de journal qu’elle génère. Nous listerons ensuite certains outils que vous trouverez utiles lors de l’opérationnalisation de vos données de journal.
- Serveur Syslog
- Configuration de journalisation HAProxy
- Format de journal HAProxy
- Proxies
- Minuteries
- État de la session à la déconnexion
- Compteurs
- Autres champs
- Activation du profilage HAProxy
- Analyse des journaux HAProxy
- HALog
- Page de statistiques HAProxy
- Tableau de bord HAProxy Enterprise En temps réel
- Conclusion
Serveur Syslog
HAProxy peut émettre un message de journal pour traitement par un serveur syslog. Ceci est compatible avec les outils syslog familiers tels que Rsyslog, ainsi que le nouveau service systemd journald. Vous pouvez également utiliser divers expéditeurs de journaux tels que Logstash et Fluentd pour recevoir des messages Syslog de HAProxy et les envoyer à un agrégateur de journaux central.
Si vous travaillez dans un environnement conteneur, HAProxy prend en charge la journalisation native dans le Cloud, ce qui vous permet d’envoyer les messages de journal à stdout et stderr. Dans ce cas, passez à la section suivante où vous verrez comment.
Avant d’examiner comment activer la journalisation via le fichier de configuration HAProxy, vous devez d’abord vous assurer qu’un serveur Syslog, tel que rsyslog, est configuré pour recevoir les journaux. Sur Ubuntu, vous installez rsyslog à l’aide du gestionnaire de paquets apt, comme ceci :
Une fois que rsyslog est installé, modifiez sa configuration pour gérer l’ingestion des messages de journal HAProxy. Ajoutez les éléments suivants à /etc/rsyslog.conf ou à un nouveau fichier dans le rsyslog.d répertoire, comme /etc/rsyslog.d/ haproxy.conf:
Ensuite, redémarrez le service rsyslog. Dans l’exemple ci-dessus, rsyslog écoute l’adresse de bouclage IP, 127.0.0.1, sur le port UDP par défaut 514. Cette configuration particulière écrit dans deux fichiers journaux. Le fichier choisi est basé sur le niveau de gravité avec lequel le message a été enregistré. Pour comprendre cela, regardez de plus près les deux dernières lignes du fichier. Ils commencent comme ceci:
La norme Syslog prescrit que chaque message enregistré doit se voir attribuer un code d’installation et un niveau de gravité. Compte tenu de l’exemple de configuration de rsyslog ci-dessus, vous pouvez supposer que nous allons configurer HAProxy pour envoyer tous ses messages de journal avec un code d’installation de local0.
Le niveau de gravité est spécifié après le code de l’installation, séparé par un point. Ici, la première ligne capture les messages à tous les niveaux de gravité et les écrit dans un fichier appelé haproxy-traffic.journal. La deuxième ligne capture uniquement les messages au niveau des avis et au-dessus, en les enregistrant dans un fichier appelé haproxy-admin.journal.
HAProxy est codé en dur pour utiliser certains niveaux de gravité lors de l’envoi de certains messages. Par exemple, il classe les messages de journal liés aux connexions et aux requêtes HTTP avec le niveau de gravité des informations. Les autres événements sont classés en utilisant l’un des autres niveaux, moins verbeux. Du plus important au moins important, les niveaux de gravité sont les suivants :
| Niveau de gravité | Journaux HAProxy |
| emerg | Erreurs telles que l’épuisement des descripteurs de fichiers du système d’exploitation. |
| alerte | Quelques rares cas où quelque chose d’inattendu s’est produit, comme l’impossibilité de mettre en cache une réponse. |
| crit | Non utilisé. |
| err | Erreurs telles que l’impossibilité d’analyser un fichier de mappage, l’impossibilité d’analyser le fichier de configuration HAProxy et l’échec d’une opération sur une table stick. |
| avertissement | Certaines erreurs importantes, mais non critiques, telles que l’échec de la définition d’un en-tête de requête ou l’échec de la connexion à un serveur de noms DNS. |
| avis | Modifie l’état d’un serveur, par exemple lorsqu’il est en HAUT ou en BAS ou lorsqu’un serveur est désactivé. D’autres événements au démarrage, tels que le démarrage des proxys et le chargement des modules sont également inclus. La journalisation de vérification de l’état, si elle est activée, utilise également ce niveau. |
| info | Détails et erreurs de la connexion TCP et de la requête HTTP. |
| debug | Vous pouvez écrire du code Lua personnalisé qui enregistre les messages de débogage |
Les distributions Linux modernes sont livrées avec le gestionnaire de services systemd, qui introduit journald pour la collecte et le stockage des journaux. Le service journald n’est pas une implémentation Syslog, mais il est compatible Syslog car il écoutera sur le même socket /dev/log. Il collectera les journaux reçus et permettra à l’utilisateur de les filtrer par code d’installation et / ou niveau de gravité en utilisant les champs journaliers équivalents (SYSLOG_FACILITY, PRIORITY).
Configuration de journalisation HAProxy
Le manuel de configuration HAProxy explique que la journalisation peut être activée en deux étapes : La première consiste à spécifier un serveur Syslog dans la section global en utilisant une directive log :
Le log la directive div> demande à HAProxy d’envoyer des journaux au serveur Syslog en écoute à 127.0.0.1:514. Les messages sont envoyés avec facility local0, qui est l’une des installations Syslog standard définies par l’utilisateur. C’est aussi l’installation que notre configuration rsyslog attend. Vous pouvez ajouter plusieurs instructions log pour envoyer la sortie à plusieurs serveurs Syslog.
Vous pouvez contrôler la quantité d’informations consignées en ajoutant un niveau Syslog à la fin de la ligne :
La deuxième étape de la configuration de la journalisation consiste à mettre à jour les différents proxys (sections frontendbackend et listen) pour envoyer des messages au(x) serveur(s) Syslog configuré(s) dans la section global. Cela se fait en ajoutant une directive log global. Vous pouvez l’ajouter à la section defaults, comme indiqué:
La directive log global dit essentiellement, utilisez la ligne log qui a été définie dans la section global. Placer une directive log global dans la section defaults équivaut à la placer dans toutes les sections proxy suivantes. Cela permettra donc de se connecter à tous les mandataires. Vous pouvez en savoir plus sur les sections d’un fichier de configuration HAProxy dans notre article de blog Les Quatre Sections essentielles d’une configuration HAProxy.
Par défaut, la sortie de HAProxy est minimale. L’ajout de la ligne option httplog à votre section defaults permettra une journalisation HTTP plus détaillée, que nous expliquerons plus en détail plus loin.
Une configuration HAProxy typique ressemble à ceci :
L’utilisation de règles de journalisation globales est la configuration HAProxy la plus courante, mais vous pouvez les placer directement dans une section frontend à la place. Il peut être utile d’avoir une configuration de journalisation différente en une seule fois. Par exemple, vous pouvez pointer vers un serveur Syslog cible différent, utiliser une fonction de journalisation différente ou capturer différents niveaux de gravité en fonction du cas d’utilisation de l’application backend. Considérons l’exemple suivant dans lequel les sections frontend, fe_site1 et fe_site2, définissent différentes adresses IP et niveaux de gravité :
Lors de la connexion à un service Syslog local, l’écriture sur un socket UNIX peut être plus rapide que le ciblage de l’adresse de bouclage TCP. Généralement, sur les systèmes Linux, un socket UNIX écoutant les messages Syslog est disponible dans /dev/log car c’est là que la fonction syslog() de la bibliothèque GNU C envoie des messages par défaut. Ciblez le socket UNIX comme ceci :
Cependant, vous devez garder à l’esprit que si vous utilisez un socket UNIX pour la journalisation et que vous exécutez en même temps HAProxy dans un environnement chrooté — ou si vous laissez HAProxy créer un répertoire chroot pour vous en utilisant la directive de configuration chroot — alors le socket UNIX doit être disponible dans ce répertoire chroot. Cela peut être fait de deux manières.
Tout d’abord, lorsque rsyslog démarre, il peut créer un nouveau socket d’écoute dans le système de fichiers chroot. Ajoutez ce qui suit à votre fichier de configuration HAProxy rsyslog :
La deuxième façon consiste à ajouter manuellement le socket au système de fichiers chroot en utilisant la commande mount avec l’option --bind.
Assurez-vous d’ajouter une entrée à votre fichier /etc/fstab ou à un fichier d’unité systemd afin que le montage persiste après un redémarrage. Une fois la journalisation configurée, vous voudrez comprendre comment les messages sont structurés. Dans la section suivante, vous verrez les champs qui composent les journaux de niveau TCP et HTTP.
Si vous devez limiter la quantité de données stockées, une façon consiste à échantillonner uniquement une partie des messages de journal. Définissez le niveau de journal sur silencieux pour un nombre aléatoire de requêtes, comme ceci :
Notez que, si possible, il est préférable de capturer autant de données que possible. De cette façon, vous n’avez pas d’informations manquantes lorsque vous en avez le plus besoin. Vous pouvez également modifier l’expression ACL afin que certaines conditions remplacent la règle.
Une autre façon de limiter le nombre de messages enregistrés consiste à définir option dontlog-normaldans votre defaults ou frontend. De cette façon, seuls les délais d’attente, les tentatives et les erreurs sont capturés. Vous ne voudriez probablement pas activer cela tout le temps, mais seulement pendant certaines périodes, par exemple lors de l’exécution de tests de benchmarking.
Si vous exécutez HAProxy à l’intérieur d’un conteneur Docker et que vous utilisez HAProxy version 1.9, au lieu d’envoyer la sortie du journal à un serveur Syslog, vous pouvez l’envoyer à stdout et/ ou stderr. Définissez l’adresse sur stdout ou stderr, respectivement. Dans ce cas, il est également préférable de définir le format du message sur raw, comme ceci:
Format de journal HAProxy
Le type de journalisation que vous verrez est déterminé par le mode proxy que vous définissez dans HAProxy. HAProxy peut fonctionner en tant que proxy de couche 4 (TCP) ou en tant que proxy de couche 7 (HTTP). Le mode TCP est la valeur par défaut. Dans ce mode, une connexion full-duplex est établie entre les clients et les serveurs, et aucun examen de couche 7 ne sera effectué. Si vous avez défini votre configuration rsyslog en fonction de notre discussion dans la première section, vous trouverez le fichier journal dans /var/log/haproxy-traffic.journal.
En mode TCP, qui est défini en ajoutant mode tcp, vous devez également ajouter l’option tcplog. Avec cette option, le format du journal est par défaut une structure qui fournit des informations utiles telles que les détails de connexion de la couche 4, les minuteries, le nombre d’octets, etc. Si vous deviez recréer ce format en utilisant log-format, qui est utilisé pour définir un format personnalisé, cela ressemblerait à ceci:
Les descriptions de ces champs se trouvent dans la documentation du format de journal TCP, bien que nous en décrirons plusieurs dans la section à venir.
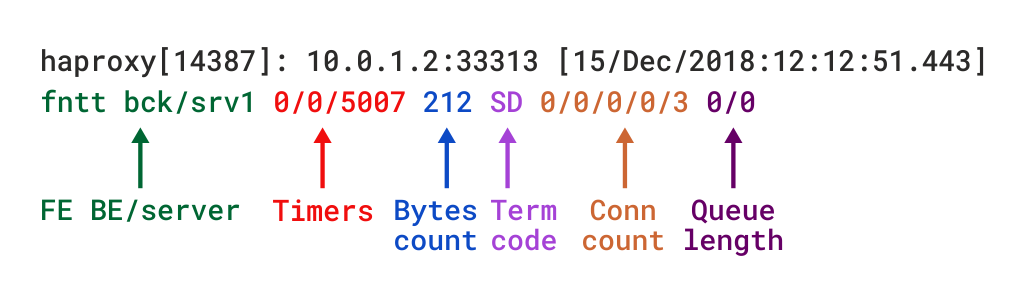
Format de journal TCP dans HAProxy
Lorsque HAProxy est exécuté en tant que proxy de couche 7 via mode http, vous devez ajouter la directive option httplog. Il garantit que les requêtes et les réponses HTTP sont analysées en profondeur et qu’aucun contenu conforme à la RFC ne sera capté. C’est le mode qui met vraiment en évidence la valeur diagnostique de l’HAProxy. Le format de journal HTTP fournit le même niveau d’informations que le format TCP, mais avec des données supplémentaires spécifiques au protocole HTTP. Si vous deviez recréer ce format en utilisant log-format, cela ressemblerait à ceci:
Des descriptions détaillées des différents champs se trouvent dans la documentation du format de journal HTTP.
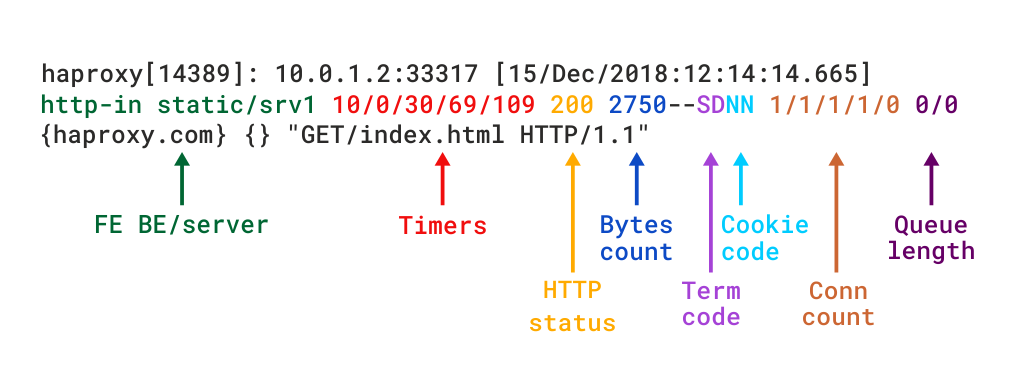
Format de journal HTTP dans HAProxy
Vous pouvez également définir un format de journal personnalisé, capturant uniquement ce dont vous avez besoin. Utilisez la directive log-format (ou log-format-sd pour le syslog de données structurées) dans votre defaults ou frontend. Lisez notre article de blog HAProxy Log Customization pour en savoir plus et voir quelques exemples.
Dans les sections suivantes, vous vous familiariserez avec les champs inclus lorsque vous utilisez option tcplog ou option httplog.
Proxies
Dans le fichier journal produit, chaque ligne commence par le frontend, le backend et le serveur auxquels la requête a été envoyée. Par exemple, si vous aviez la configuration HAProxy suivante, vous verriez des lignes décrivant les demandes comme étant acheminées via le frontend http-in vers le backend statique, puis vers le serveur srv1.
Cela devient une information vitale lorsque vous devez savoir où une demande a été envoyée, par exemple lorsque vous voyez des erreurs qui n’affectent que certains de vos serveurs.
Minuteries
Les minuteries sont fournies en millisecondes et couvrent les événements qui se produisent pendant une session. Les minuteries capturées par le format de journal TCP par défaut sont Tw/Tc/Tt. Ceux fournis par le format de journal HTTP par défaut sont TR/Tw/Tc/Tr/Ta. Ceux-ci se traduisent par:
| Minuterie | Signifiant |
| TR | Le temps total pour obtenir la demande du client (mode HTTP uniquement). |
| Tw | Le temps total passé dans les files d’attente en attente d’un emplacement de connexion. |
| Tc | Le temps total pour établir la connexion TCP au serveur. |
| Tr | Le temps de réponse du serveur (mode HTTP uniquement). |
| Ta | Le temps total d’activité de la requête HTTP (mode HTTP uniquement). |
| Tt | La durée totale de la session TCP, entre le moment où le proxy l’a acceptée et le moment où les deux extrémités ont été fermées. |
Vous trouverez une description détaillée de toutes les minuteries disponibles dans la documentation HAProxy. Le diagramme suivant montre également où le temps est enregistré lors d’une seule transaction de bout en bout. Notez que les lignes violettes sur les bords indiquent des minuteries.
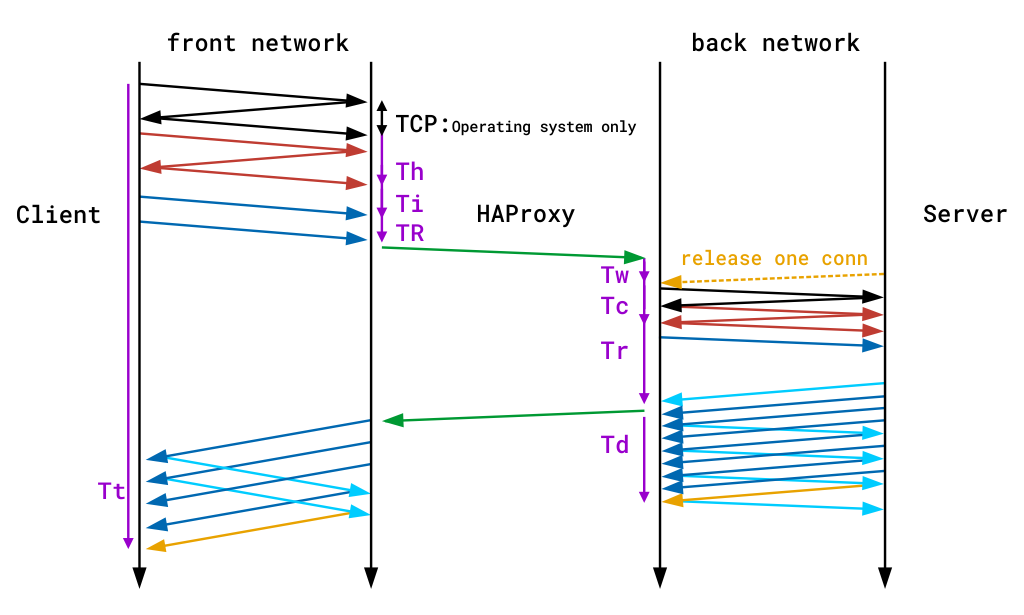
Enregistrement de l’heure lors d’une seule transaction de bout en bout
État de la session à la déconnexion
Les journaux TCP et HTTP incluent un code d’état de terminaison qui vous indique la façon dont la session TCP ou HTTP s’est terminée. C’est un code à deux caractères. Le premier caractère signale le premier événement qui a provoqué la fin de la session, tandis que le second indique l’état de la session TCP ou HTTP lorsqu’elle a été fermée.
Voici quelques exemples de code de terminaison:
| Code à deux caractères | Signification |
| – | Terminaison normale des deux côtés. |
| cD | Le client n’a pas envoyé ni accusé de réception de données et finalement timeout client a expiré. |
| SC | Le serveur a explicitement refusé la connexion TCP. |
| PC | Le proxy a refusé d’établir une connexion au serveur car la limite de socket du processus a été atteinte lors de la tentative de connexion. |
Il existe une grande variété de raisons pour lesquelles une connexion peut avoir été fermée. Des informations détaillées sur tous les codes de terminaison possibles peuvent être trouvées dans la documentation HAProxy.
Compteurs
Les compteurs indiquent l’état du système lorsqu’une requête est passée. HAProxy enregistre cinq compteurs pour chaque connexion ou demande. Ils peuvent être précieux pour déterminer la quantité de charge placée sur le système, où le système est en retard et si les limites ont été atteintes. Lorsque vous regardez une ligne dans le journal, vous verrez les compteurs répertoriés sous la forme de cinq nombres séparés par des barres obliques: 0/0/0/0/0.
En mode TCP ou HTTP, ceux-ci se décomposent comme suit :
- Le nombre total de connexions simultanées sur le processus HAProxy lorsque la session a été enregistrée.
- Le nombre total de connexions simultanées acheminées via ce
frontendlorsque la session a été enregistrée. - Le nombre total de connexions simultanées acheminées vers ce
backendlorsque la session a été enregistrée. - Le nombre total de connexions simultanées toujours actives sur ce
serverlorsque la session a été enregistrée. - Le nombre de tentatives tentées lors de la tentative de connexion au serveur principal.
Autres champs
HAProxy n’enregistre pas tout prêt à l’emploi, mais vous pouvez le modifier pour capturer ce dont vous avez besoin. Un en-tête de requête HTTP peut être enregistré en ajoutant la directive http-request capture :
Le journal affichera les en-têtes entre accolades et séparés par des symboles de canal. Vous pouvez voir ici les en-têtes Host et User-Agent pour une requête:
Un en-tête de réponse peut être enregistré en ajoutant une directive http-response capture :
Dans ce cas, vous devez également ajouter une directive declare capture response, qui alloue un emplacement de capture où l’en-tête de réponse, une fois arrivé, peut être stocké. Chaque emplacement que vous ajoutez se voit automatiquement attribuer un identifiant à partir de zéro. Référencez cet ID lors de l’appel de http-response capture. Les en-têtes de réponse sont enregistrés après les en-têtes de requête, dans un ensemble distinct d’accolades.
Les valeurs des cookies peuvent être enregistrées de la même manière avec la directive http-request capture.
Tout ce qui est capturé avec http-request capture, y compris les en-têtes HTTP et les cookies, apparaîtra dans le même ensemble d’accolades. Il en va de même pour tout ce qui est capturé avec http-response capture.
Vous pouvez également utiliser http-request capture pour consigner les données échantillonnées des tables stick. Si vous suiviez les taux de demandes des utilisateurs avec un stick-table, vous pouvez les enregistrer comme ceci :
Ainsi, faire une demande à une page Web contenant le document HTML et deux images montrerait le taux de demandes simultanées de l’utilisateur incrémentant à trois:
Vous pouvez également enregistrer les valeurs des méthodes de récupération, par exemple pour enregistrer la version de SSL/TLS utilisée (notez qu’il existe une variable de journal intégrée pour obtenir cela appelée %sslv):
Les variables définies avec http-request set-var peuvent également être enregistrées.
Les expressions ACL sont évaluées à true ou false. Vous ne pouvez pas les enregistrer directement, mais vous pouvez définir une variable selon que l’expression est vraie ou non. Par exemple, si l’utilisateur visite /api, vous pouvez définir une variable appelée req.is_api sur une valeur de Is API, puis la capturer dans les journaux.
Activation du profilage HAProxy
Avec la sortie de HAProxy 1.9, vous pouvez enregistrer le temps CPU consacré au traitement d’une requête dans HAProxy. Ajoutez la directive profiling.tasks à votre section global :
Il existe de nouvelles méthodes de récupération qui exposent les métriques de profilage :
| Méthode de récupération | Description |
date_us |
La partie microsecondes de la date. |
cpu_calls
|
Le nombre d’appels à la tâche traitant le flux ou la demande en cours depuis son attribution. Il est réinitialisé à chaque nouvelle demande sur la même connexion. |
cpu_ns_avg
|
Le nombre moyen de nanosecondes passées à chaque appel à la tâche traitant le flux ou la demande en cours. |
cpu_ns_tot
|
Le nombre total de nanosecondes passées à chaque appel à la tâche traitant le flux ou la demande en cours. |
lat_ns_avg
|
Le nombre moyen de nanosecondes passées entre le moment où la tâche gérant le flux est réveillée et le moment où elle est effectivement appelée. |
lat_ns_tot
|
Le nombre total de nanosecondes entre le moment où la tâche gérant le flux est réveillée et le moment où elle est effectivement appelée. |
Ajoutez-les à vos messages de journal comme ceci :
C’est un excellent moyen de déterminer quelles demandes coûtent le plus cher à traiter.
Analyse des journaux HAProxy
Comme vous l’avez appris, HAProxy a beaucoup de champs qui fournissent une quantité énorme d’informations sur les connexions et les requêtes. Cependant, les lire directement peut entraîner une surcharge d’informations. Souvent, il est plus facile de les analyser et de les agréger avec des outils externes. Dans cette section, vous verrez certains de ces outils et comment ils peuvent tirer parti des informations de journalisation fournies par HAProxy.
HALog
HALog est un outil d’analyse de logs petit mais puissant livré avec HAProxy. Il a été conçu pour être déployé sur des serveurs de production où il peut aider au dépannage manuel, par exemple lors de problèmes en direct. Il est extrêmement rapide et capable d’analyser les journaux TCP et HTTP à 1 à 2 Go par seconde. En lui transmettant une combinaison d’indicateurs, vous pouvez extraire des informations statistiques des journaux, y compris les requêtes par URL et les requêtes par adresse IP source. Ensuite, vous pouvez trier par temps de réponse, taux d’erreur et code de terminaison.
Par exemple, si vous souhaitez extraire des statistiques par serveur des journaux, vous pouvez utiliser la commande suivante:
Ceci est utile lorsque vous devez analyser les lignes de journal par code d’état et découvrir rapidement si un serveur donné est malsain (par exemple, renvoyer trop de réponses 5xx). Ou, un serveur peut refuser trop de demandes (réponses 4xx), ce qui est le signe d’une attaque par force brute. Vous pouvez également obtenir le temps de réponse moyen par serveur avec la colonne avg_rt, ce qui est utile pour le dépannage.
Avec HALog, vous pouvez obtenir des statistiques par URL en utilisant la commande suivante:
La sortie affiche le nombre de requêtes, le nombre d’erreurs, le temps de calcul total, le temps de calcul moyen, le temps de calcul total des requêtes réussies, le temps de calcul moyen des requêtes réussies, le nombre moyen d’octets envoyés et le nombre total d’octets envoyés. En plus de l’analyse des statistiques du serveur et des URL, vous pouvez appliquer plusieurs filtres pour faire correspondre les journaux avec un temps de réponse donné, un code d’état HTTP, un code de fin de session, etc.
Page de statistiques HAProxy
L’analyse des journaux avec HALog n’est pas le seul moyen d’extraire des métriques de HAProxy. La page de statistiques HAProxy peut être activée en ajoutant la directive stats enable à une section frontend ou listen. Il affiche les statistiques en direct de vos serveurs. La section suivante listen démarre la page de statistiques à l’écoute sur le port 8404:
La page de statistiques est très utile pour obtenir des informations instantanées sur le trafic circulant à travers HAProxy. Cependant, il ne stocke pas ces données et n’affiche les données que pour un seul équilibreur de charge.
Tableau de bord HAProxy Enterprise En temps réel
Si vous utilisez HAProxy Enterprise, vous avez accès au Tableau de bord en temps réel. Alors que la page Statistiques affiche des statistiques pour une seule instance de HAProxy, le tableau de bord en temps réel agrège et affiche des informations sur un cluster d’équilibreurs de charge. Cela permet d’observer facilement la santé de tous vos serveurs à partir d’un seul écran. Les données peuvent être visualisées jusqu’à 30 minutes.
Le tableau de bord stocke et affiche des informations sur l’état du service, les taux de demandes et la charge. Il facilite également l’exécution des tâches administratives, telles que l’activation, la désactivation et la vidange des backends. En un coup d’œil, vous pouvez voir quels serveurs sont en service et pour combien de temps. Vous pouvez également afficher les données de table de bâton, qui, en fonction du suivi de la table de bâton, peuvent vous afficher les taux d’erreur, les taux de demandes et d’autres informations en temps réel sur vos utilisateurs. Les données de table de bâton peuvent également être agrégées.
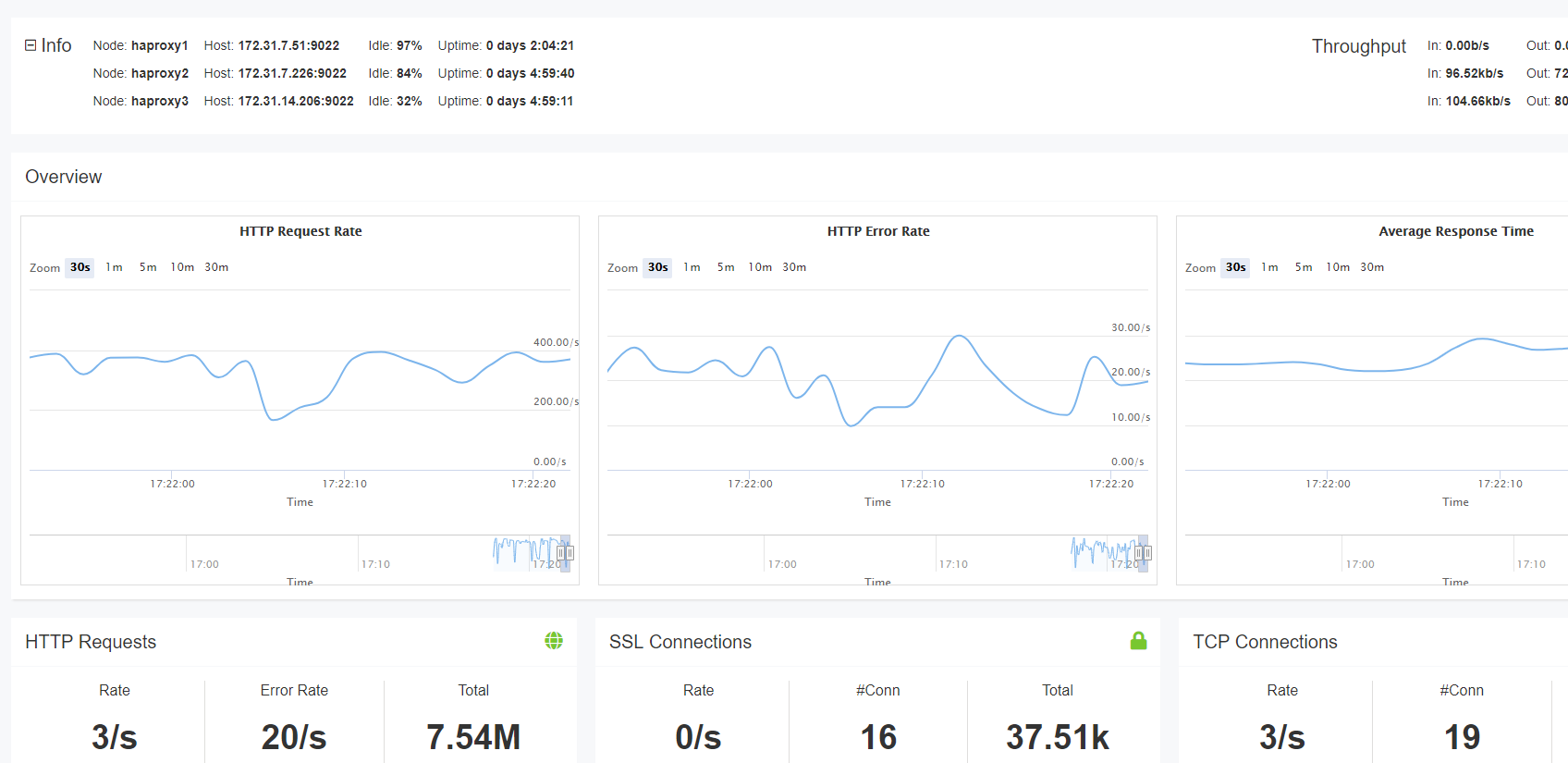
Le Tableau de bord en temps réel dans HAProxy Enterprise
Le Tableau de bord en temps réel est l’un des nombreux add-ons disponibles avec HAProxy Enterprise.
Conclusion
Dans cet article de blog, vous avez appris à configurer la journalisation HAProxy pour obtenir une observabilité sur votre équilibreur de charge, qui est un composant essentiel de votre infrastructure. HAProxy émet des messages Syslog détaillés lorsqu’il fonctionne en mode TCP et HTTP. Ceux-ci peuvent être envoyés à un certain nombre d’outils de journalisation, tels que rsyslog.
HAProxy est livré avec l’utilitaire de ligne de commande HALog, qui simplifie l’analyse des données de journal lorsque vous avez besoin d’informations sur les types de réponses que les utilisateurs obtiennent et la charge sur vos serveurs. Vous pouvez également obtenir un aperçu de l’état de santé de vos serveurs en utilisant la page de statistiques HAProxy ou le tableau de bord HAProxy Enterprise en temps réel.
Vous voulez savoir quand un contenu comme celui-ci est publié? Abonnez-vous à ce blog ou suivez-nous sur Twitter. Vous pouvez également participer à la conversation sur Slack ! HAProxy Enterprise combine HAProxy avec des fonctionnalités de classe entreprise, telles que le tableau de bord en temps réel et le support premium. Contactez-nous pour en savoir plus ou inscrivez-vous pour un essai gratuit dès aujourd’hui!